

前回アレクサとChatGPTを繋げてたけど、声が機械的すぎてイマイチ会話に感情がこもらないんだよね。

そうだね〜。アレクサの声はどうしても無機質に感じてしまうよね。
もっと感情のこもった声でChatGPTからの回答をVOICEVOXで音声合成して応答するようにカスタマイズしてみようか!

VOICEVOXって何なの?

入力したテキストを様々なキャラクターの声に変換して出力してくれるテキスト読み上げソフトウェアのことだよ。
最近はYoutubeでも「ずんだもん解説動画」が流行っているね。

今回は、VOICEVOXで使えるキャラクター「ずんだもん」の声をアレクサから返ってくるようにしてみたよ。

ちなみに、東北地方応援キャラクター「東北ずん子」の関連キャラクターだそうです。

感情のこもった声でChatGPTからの応答を返してあげるのだ!
おお!!ちゃんとアレクサじゃなくて、キャラクターの可愛い声で返事してくれるんだね!
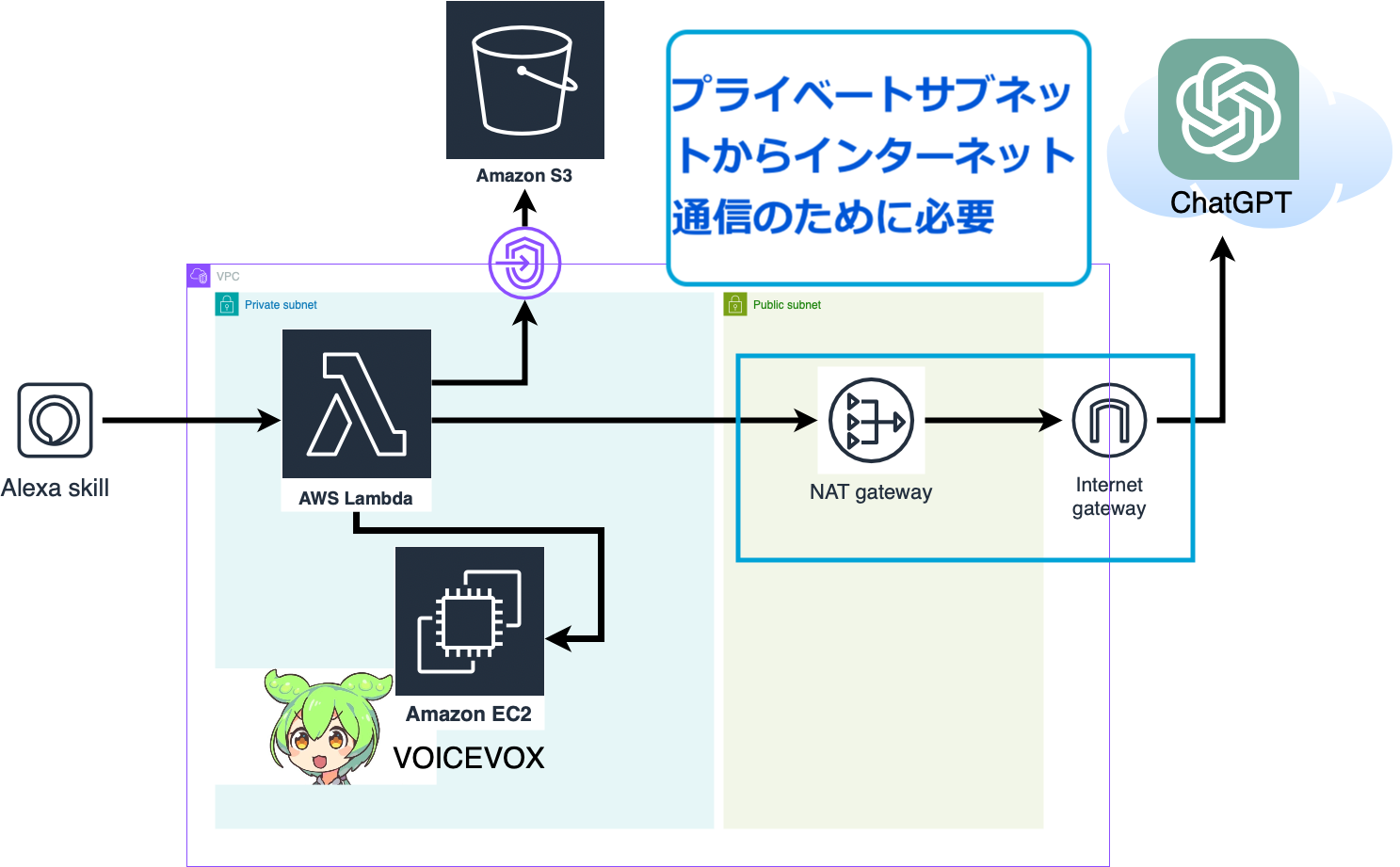
Alexaのカスタムスキルを作成し、アレクサとChatGPTとVOICEVOXを連携してみました。
本記事では、AWSの構成図や処理の流れ、実装手順などをご紹介します。
Contents
構成と処理の流れ
主な構成要素は以下のとおりです。
- アレクサ
- Lambda
- ChatGPTのAPI
- EC2(VOICEVOX)
- S3
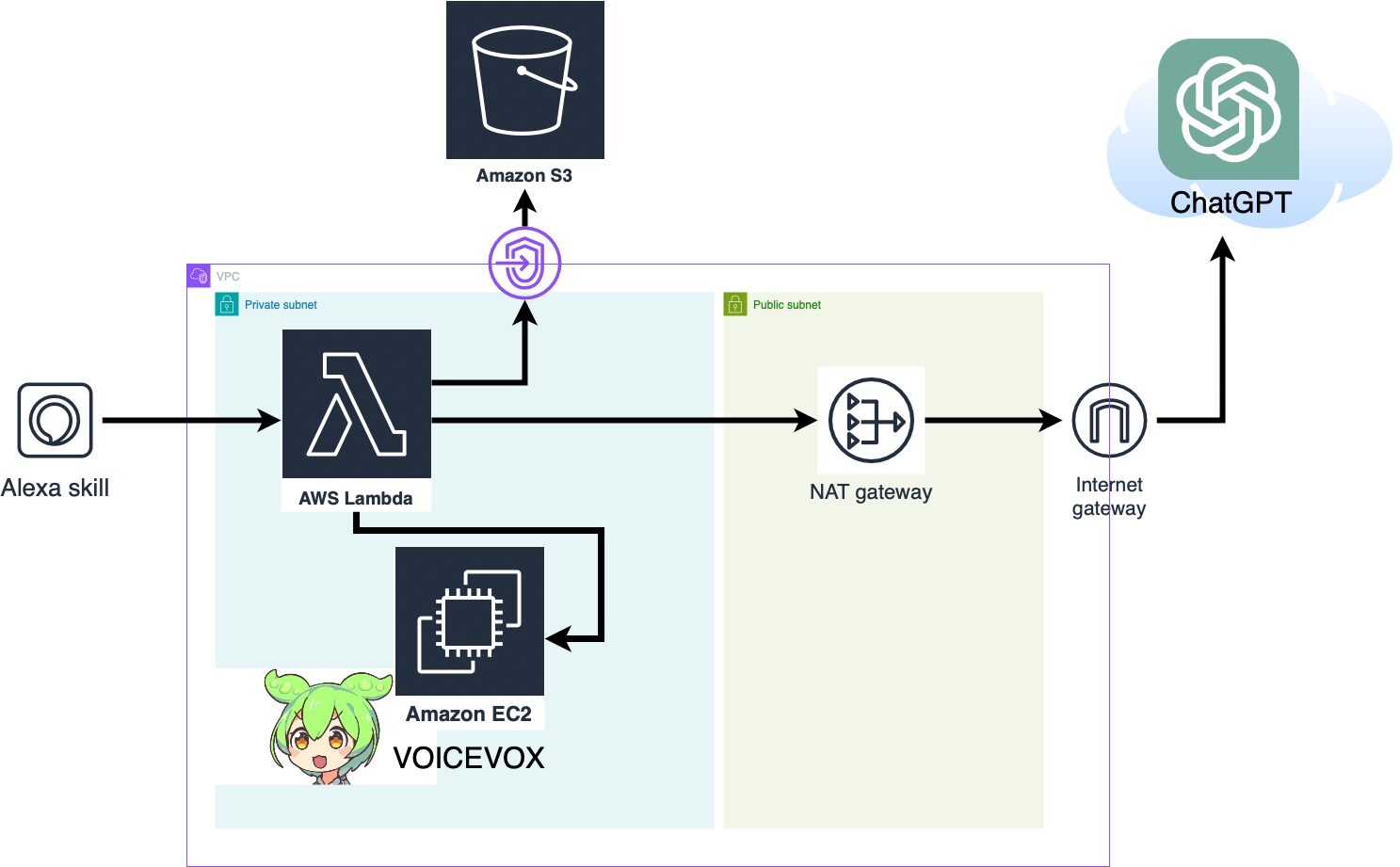
- アレクサスキルでLambda処理を呼び出す
- LambdaとChatGPT間でやりとり
- EC2でVOICEVOXエンジン起動、音声合成
- 合成音声データをEC2からLambdaに渡す
- 音声データをmp3としてS3に格納
- S3から呼び出したmp3を、アレクサで再生
Alexaのカスタムスキル作成

- アレクサスキルを作成
- アレクサスキルとLambdaの紐付け
アレクサスキルを作成
Alexaのカスタムスキルとは、自身で実装した処理に従ってアレクサが応答するというものです。
Alexa Developer Consoleから、カスタムスキルを作成することができます。
今回は、voicevox_chatgptという名前でアレクサスキルを作成しました。
アレクサスキルとLambdaの紐付け
アレクサスキルのEndpointから確認できるDefault Regionは、Lambda関数のARNと一致していることを確認してください。


本記事では、アレクサからLambda処理を呼び出すための関数を作成した後の手順を主に紹介します。
カスタムスキル作成の具体的な手順は、以下の記事をご確認ください。

Lambdaの作成・設定

Lambda関数では、実際の処理を実装します。
今回はアレクサで読み取った音声を入力として、ChatGPT、VOICEVOXで出力ファイルを作成し、最後にアレクサから応答を返す処理をPythonにて実装します。
- Pythonコード作成
- レイヤーの設定(Pythonライブラリ)
- LambdaのVPC設定
- OpenAIの環境変数を設定
Pythonコードの作成
Alexaからの応答をChatGPTおよびVOICEVOXに連携するためのコードは、以下のリンク先のコードを参考にしてください。
- リンク:https://github.com/my-repo-441/alexa-voicevox-chatgpt
- コード:
・lambda_function.py(Alexaから呼び出されるコード)
・chatgpt_voicevox.py(VOICEVOX(EC2上で起動したもの)と連携するためのコード)
コードをLambda関数の画面にて作成します。
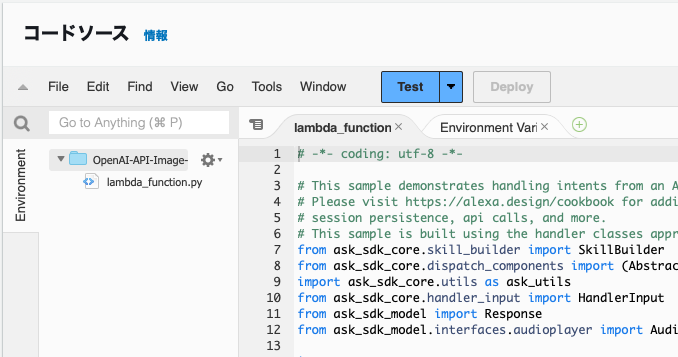
レイヤーの設定
以下をLambdaのレイヤーに登録します。
上記は、Pythonの実行に必要なライブラリをzip化したものです。(openaiなど)
- リンク:https://github.com/my-repo-441/alexa-voicevox-chatgpt/tree/main/layer
- ライブラリが入ったzip:
・ffmpeg-6506d2b4-dc40-46a2-90f2-f15f12949bbe.zip
・python-2.zip
・python.zip

Lambdaにレイヤーとして登録する際のファイル容量制限に伴い、小分けにしています。(python.zipとpython2.zipは、検証の時に色々試しながら実装したため、重複したライブラリが含まれており、正直あまり中身の整理ができていませんが、ご容赦ください。。)
Lambdaのコンソール画面から、レイヤーを選択します。

「レイヤーの作成」を押下し、githubからダウンロードしたzipファイルをアップロードしてください。この時、ランタイムはPython3.8としてください。
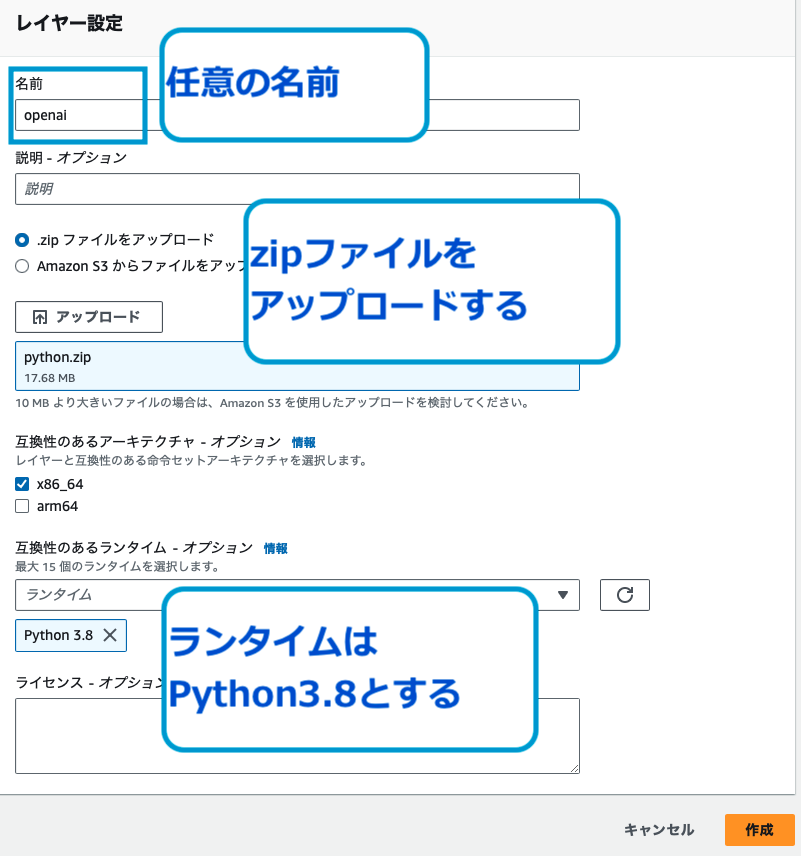
Lambda関数画面の一番下にある「レイヤーの追加」を選択し、今回用意した3つのzipファイルで作成したレイヤーを追加します。

これで作成したLambda関数にて、レイヤーに登録したライブラリの使用が可能になります。
LambdaのVPC設定
EC2とLambdaが接続するためには、LambdaとEC2が同じVPC内にある必要があります。
(LambdaとEC2のプライベートIPの連携のため)
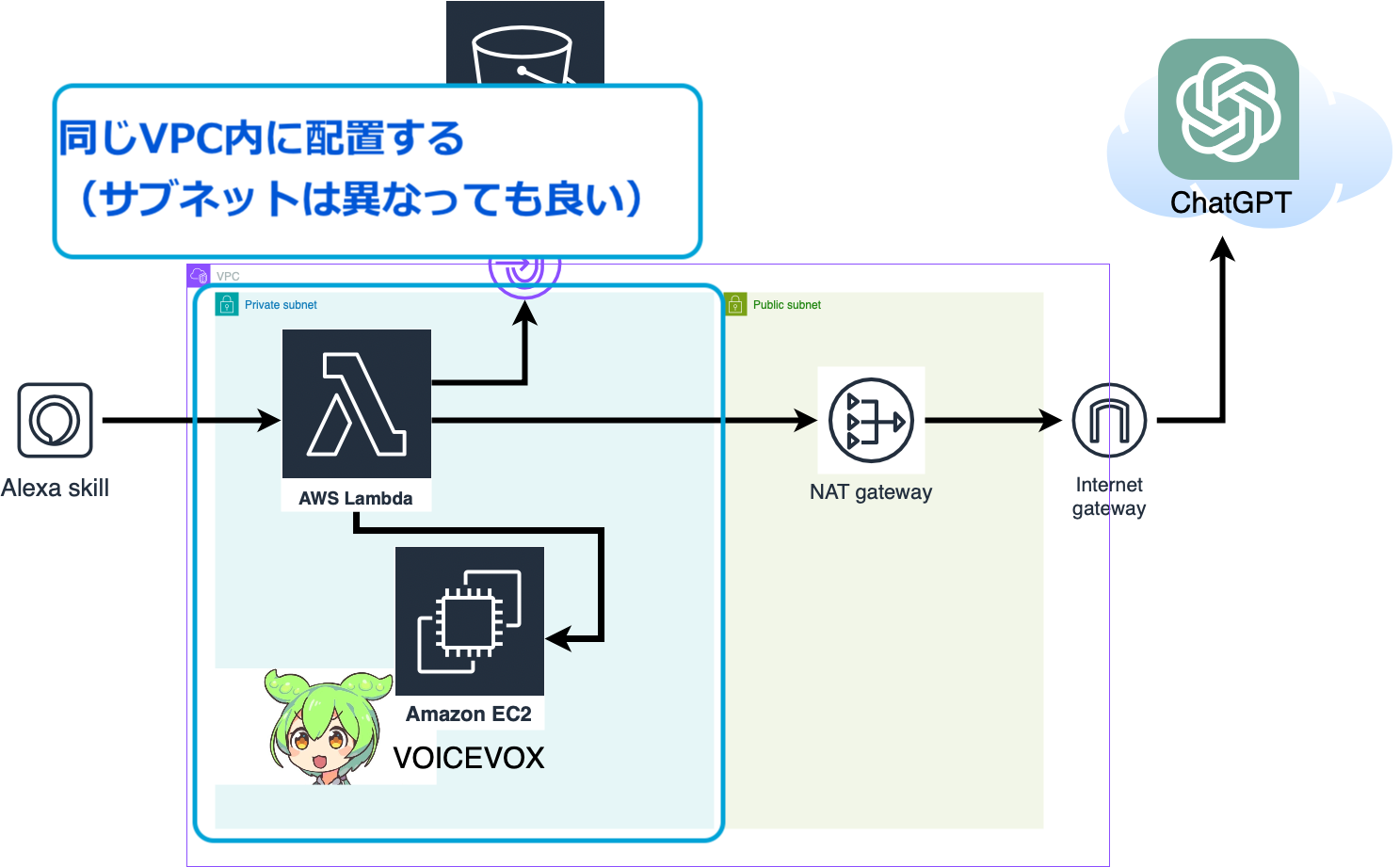
Lambdaの「設定」から、「VPC」を選択します。
なお、セキュリティグループは以下を満たしている必要があります。
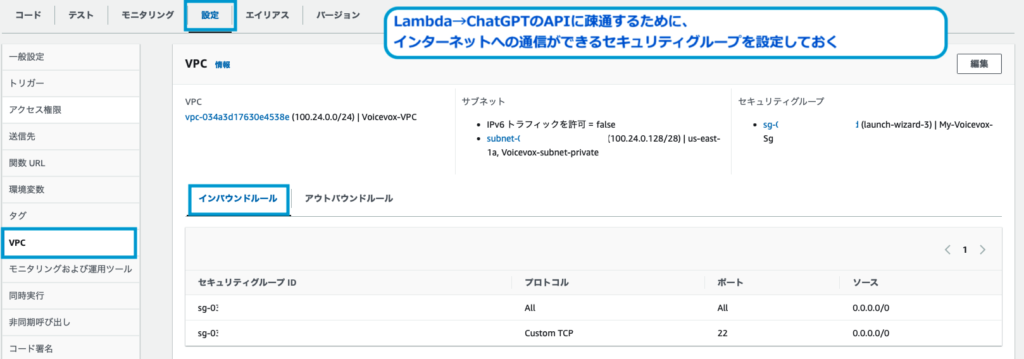
- LambdaからChatGPTのAPIに通信するためのインターネットへのアウトバウンド許可
なお今回の構成の場合は、NAT Gatewayを経由してインターネットに接続するため、最低限、NAT Gatewayへの疎通ができる設定であればOKです。 - LambdaからEC2の通信を許可するためのアウトバウンド許可
(VOICEVOXへの通信)

今回はセキュリティグループの設定を調整するのが面倒だったので、全ての通信を許可する構成としていますが、セキュリティ担保を取りたい場合は、最低限のSG設定する方が良いと思います。
OpenAIのAPIキーを環境変数として設定
Lambdaの「設定」から、「環境変数」を選択します。
以下のように、OpenAIのAPIキーを環境変数として追加します。
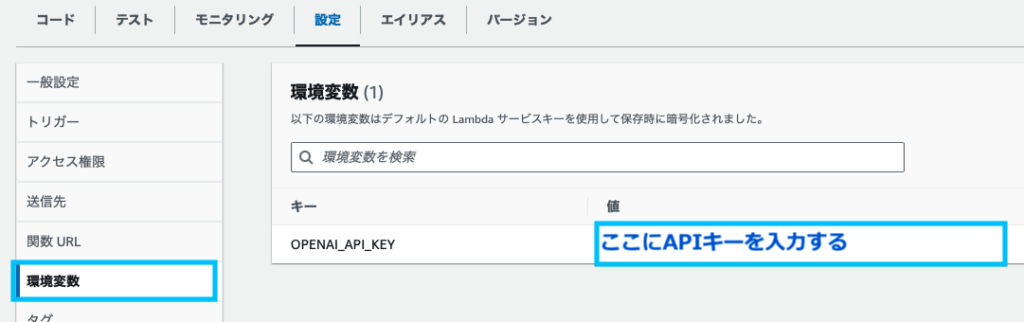
上記で追加した環境変数は、コードから以下のようにして呼び出すことができます。
import os
openai.api_key = os.getenv('OPENAI_API_KEY')コード上に直接APIキーを記載するのは非常に危険なので、環境変数として設定しておきましょう。
NAT Gatewayの設定
ChatGPTのAPIを使ってインターネットと通信するためには、パブリックサブネットにNATゲートウェイを設定する必要があります。
(プライベートサブネット内のLambdaがインターネットと応答できるようにするため)
- プライベートサブネットのLambda⇔パブリックサブネットのNAT Gateway⇔Internet Gateway⇔ChatGPTという経路を設定する。
- NATゲートウェイの作成
- ルートテーブルの編集
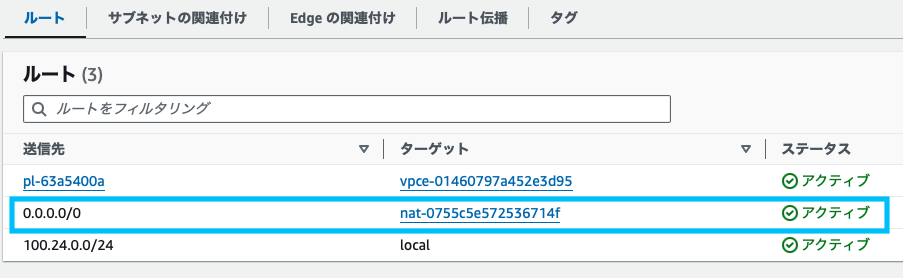
NATゲートウェイの作成
VPCのコンソール画面から、NATゲートウェイを選択します。
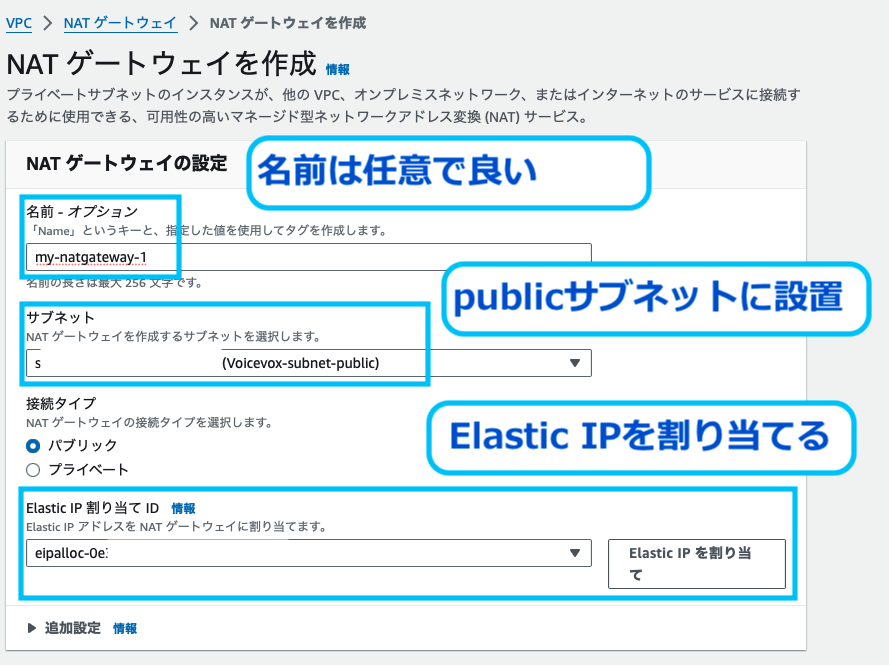
NATゲートウェイを作成します。

NATゲートウェイは、EC2とLambdaを設定したのと同じVPC内のパブリックサブネットに設定します。

ルートテーブルの編集
同様に「VPC」コンソール画面から、ルートテーブルを編集します。

修正するルートテーブルは、LambdaとEC2を設定しているのと同じVPCのプライベートサブネッとを選択します。(NATゲートウェイを設置したパブリックサブネットではないので、注意してください。)
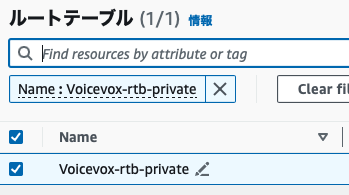
「ルート」タブ画面にて「編集」を押下し、先ほど作成したNATゲートウェイをターゲットに設定します。
送信先はインターネットなので、0.0.0.0/0を設定します。
EC2の起動&設定

VOICEVOXはサーバ上で音声合成用のエンジンを立ち上げて使用します。
(今回は、VOICEVOXのDockerイメージを使います。)
そのためのEC2起動手順と設定方法をご紹介します。
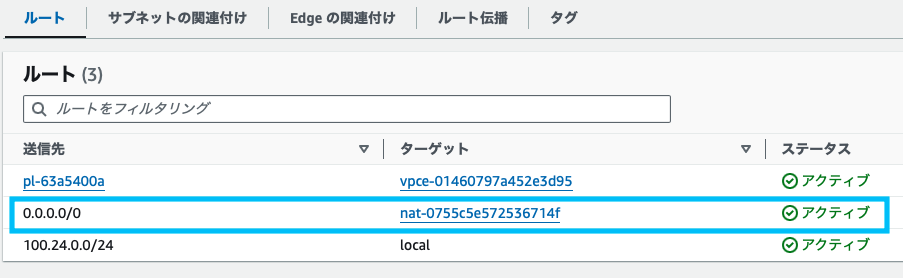
- EC2の起動(Lambdaを起動させたリージョンと同様のリージョンであることを確認)
- EC2にPython3.11をインストール
- EC2上でVOICEVOXを起動
EC2の起動
EC2のコンソール画面にて、「インスタンスを起動」を押下します。

ここで起動したEC2上で、VOICEVOXによる音声加工処理をします。
EC2を起動するリージョンが、Lambdaと同じリージョンであることを確認してください。今回の場合は、us-east-1(バージニア北部)で作成しています。
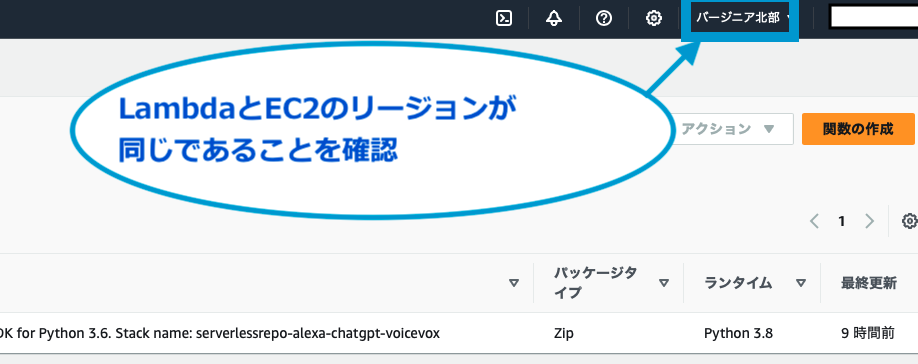
EC2の名前は任意で大丈夫です。
今回は分かりやすいように、voicevox-alexa-lambdaという名前にしておきました。
OSは「Amazon Linux 2023 AMI」を選択してください。
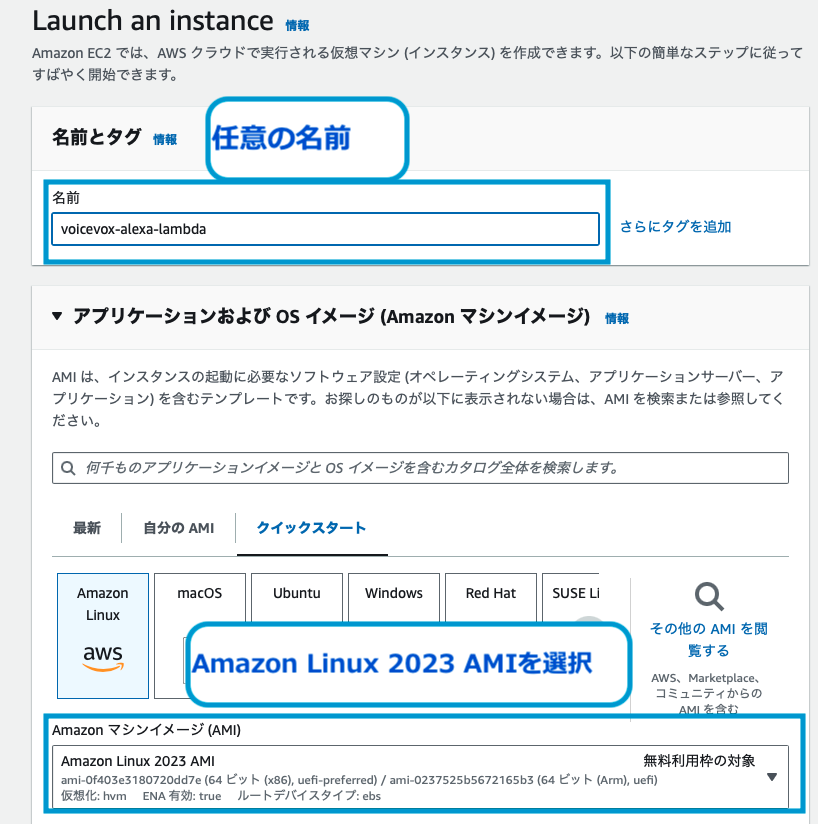
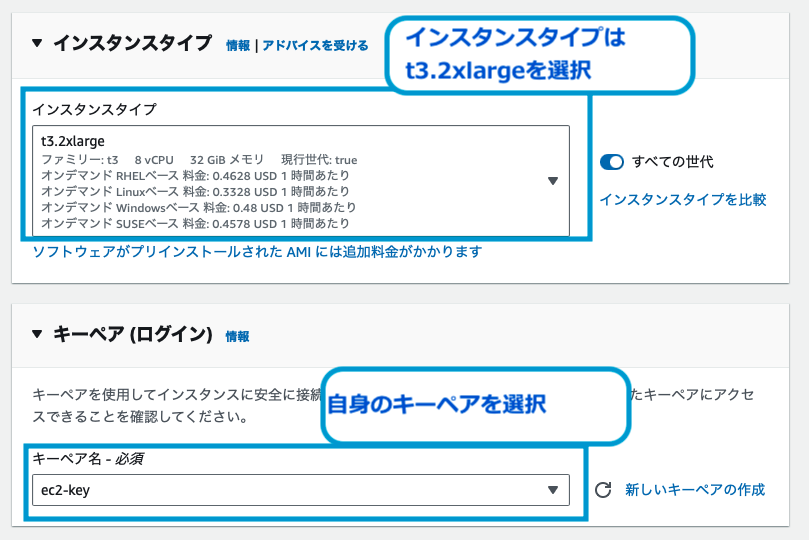
インスタンスタイプは、t3.2xlargeを選択しました。
VOICEVOXによる音声合成処理を実施するので、少しスペックが高めのインスタンスタイプを選択すると良いでしょう。
VPCは、Lambdaと同じものを選択をします。
このEC2は、Lambdaとの連携ができればいいので、サブネットはどこでも問題ありません。
安全性を担保するには、プライベートサブネットに配置しておけば良いでしょう。

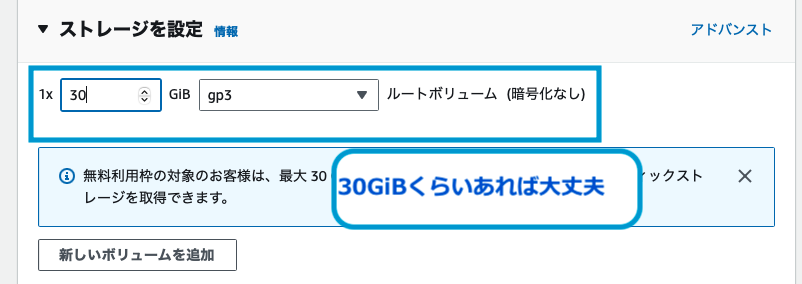
ストレージは30GiBくらいあれば大丈夫です。
(VOICEVOXが起動できるくらいのストレージ)
EC2にPython3.11をインストール
まず、起動したEC2にSSH接続します。
EC2上で以下のコマンドを実行し、Python3.11をインストールします。
"""Python3.11のインストール"""
#コンパイルに必要な開発ツールをインストール
sudo yum groupinstall "Development Tools"
#Python のビルドに必要なライブラリをインストール
sudo yum install -y openssl-devel bzip2-devel libffi-devel
# Python 3.11 のソースコードをダウンロード
cd /usr/src
sudo wget https://www.python.org/ftp/python/3.11.8/Python-3.11.8.tgz
#ダウンロードした tar ファイルを展開
sudo tar xzf Python-3.11.8.tgz
#ソースコードディレクトリに移動して、ビルドとインストール
cd Python-3.11.8
sudo ./configure --enable-optimizations
sudo make altinstall
"""Python バージョンの切り替え"""
#現在のシンボリックリンクの削除
sudo rm /usr/bin/python
#新しいシンボリックリンクの作成
sudo ln -s /usr/local/bin/python3.11 /usr/bin/python#pythonインストール確認
python --version
Python 3.11.8と表示されればインストール成功している。EC2上でVOICEVOXを起動

以下のコマンドで、Dockerコマンドをインストールします。
その後、VOICEVOXのコンテナイメージを起動させます。
"""VOICEVOXのコンテナをインストール"""
#dockerのインストール
sudo yum install docker
#dockerの起動
sudo service docker start
#VoicevoxのDockerImageを取得
sudo docker pull voicevox/voicevox_engine:cpu-ubuntu20.04-latest
#pullしたDockerの実行(100.24.0.5の部分は自身のEC2のプライベートIPアドレス)
sudo docker run --rm -it -p '100.24.0.5:50021:50021' voicevox/voicevox_engine:cpu-ubuntu20.04-latest
""""""VOICEVOXのイメージの起動が成功すると、以下のような画面が表示されます。

S3へのmp3連携

- VPCエンドポイントを作成して、S3とLambdaの経路を設定
- VPCのDNS名前解決を「有効」に設定
- S3バケットの作成
- VPCエンドポイントの作成
(プライベートサブネットに作成する) - 音声合成したデータをmp3としてS3に格納
(Lambdaの手順でコード実装済み) - S3から呼び出したmp3を、アレクサで再生
(Lambdaの手順でコード実装済み)
S3バケットの作成
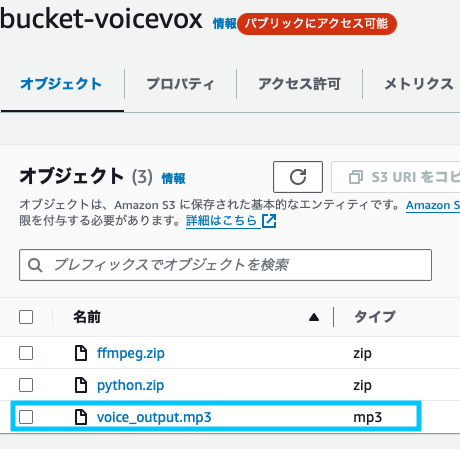
S3コンソール画面から、S3バケットを作成します。
VOICEVOXで作成されたmp3ファイルを格納するためのものです。
S3バケットは、Lambdaレイヤーの呼び出し先として使うこともできます。
容量の大きいライブラリをレイヤーとして登録したい場合は、作成したS3バケットを使うと良いでしょう。
VPCエンドポイントの作成
VPCのコンソール画面から、VPCエンドポイントを作成する。
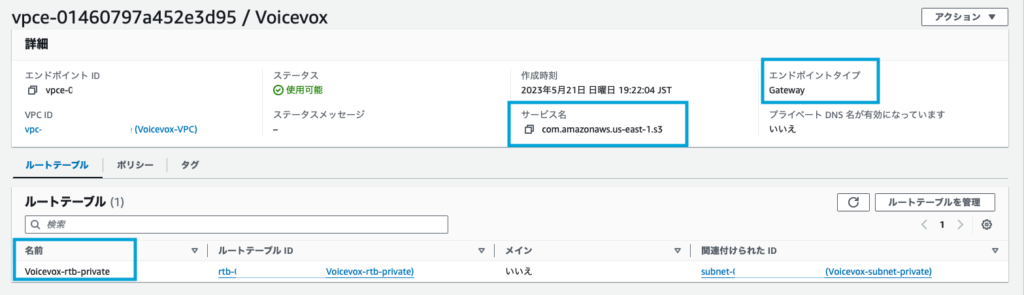
- 関連付けるサブネット:プライベートサブネット
- サービス名:com.amazonaws.us-east-1.s3(バージニア北部の場合)
- エンドポイントタイプ:Gateway
音声合成したデータをmp3としてS3に格納
VOICEVOX合成後の音声データを、Lambdaを通してmp3に変換し、S3に格納します。
アレクサスキルの実装に使うLambdaは音声再生のためのソフトを内部に持っておらず、音声を再生するためには、mp3などの音声ファイルを再生する必要があるからです。
(実はもっと良い方法はある気がしますが、今回はこれしか方法が見つからなかったです。。)
#S3に音声データをmp3として格納
s3 = boto3.client('s3', region_name='us-east-1')
bucket_name = 'bucket-voicevox'
object_name = 'voice_output.mp3'
s3.upload_fileobj(audio, bucket_name, object_name)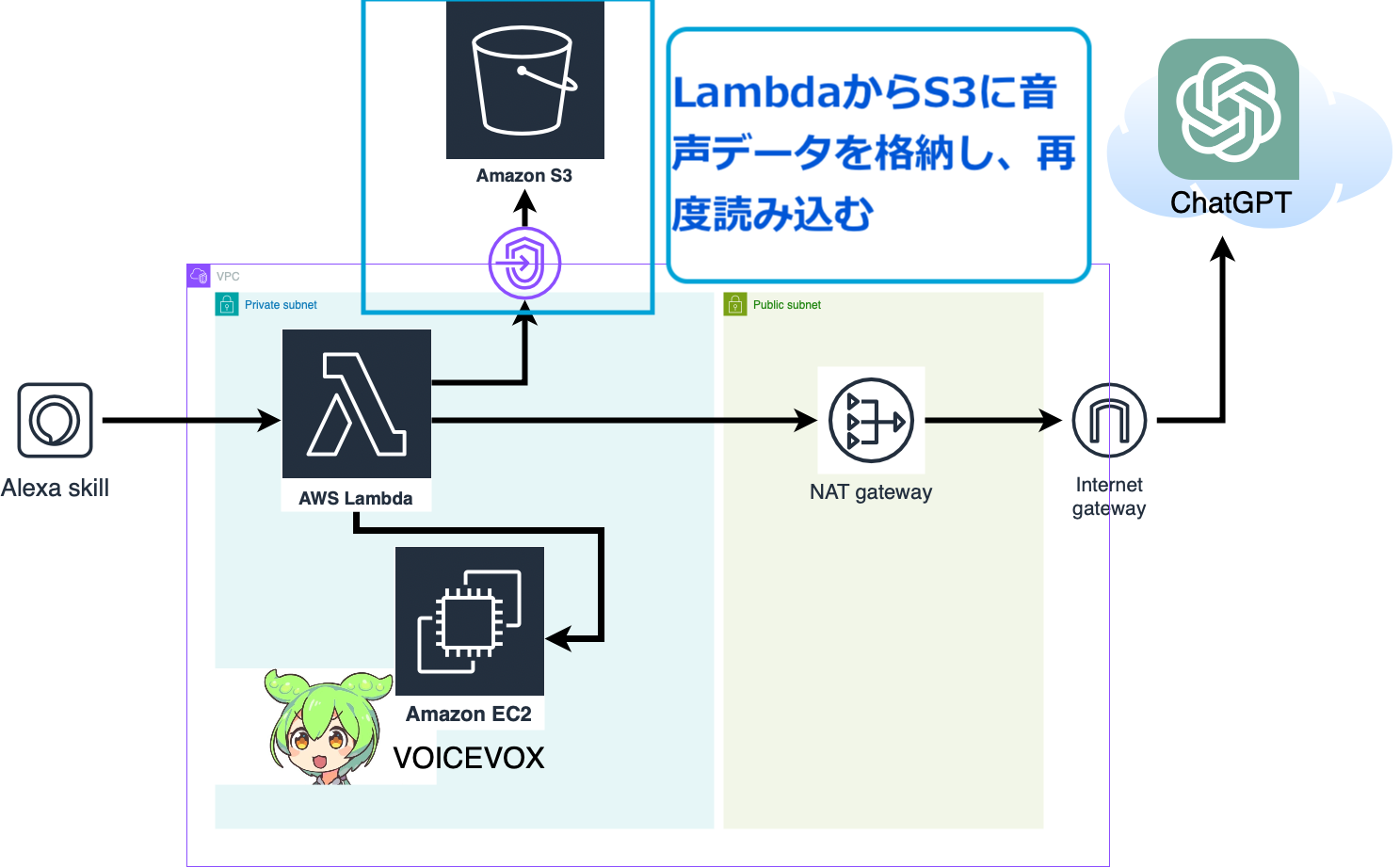
S3から呼び出したmp3を、アレクサで再生
S3上に格納したmp3をリンク先を指定して呼び出すことで、アレクサ上で音声ファイルを再生することができます。
具体的には、下記のコードが該当します。
#speakでSSMLを使用して再生
speech_text = '<audio src=\"' + html.escape(audio_url) + '\"/>'アレクサスキルのテスト
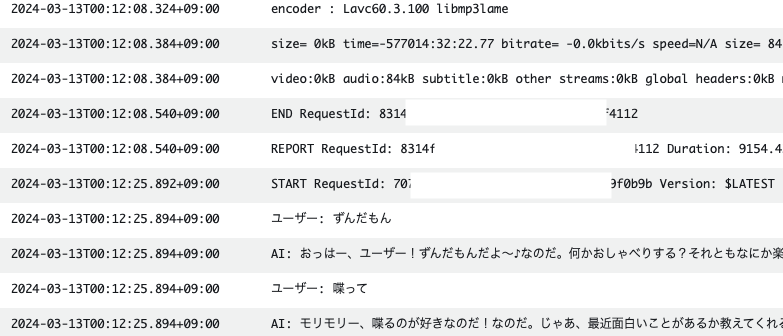
上記の構成を実際にテストした結果がこちらです。
こちらの呼びかけに対して、ずんだもんの声で応答を返してくれていることがわかります。
またChatGPTの役割に設定した、語尾に「なのだ。」をつけてというのもしっかりと反映されていることが確認できます。
ChatGPTからの応答カスタマイズ
カスタマイズ方法
Alexaに呼びかけたユーザの声を、ChatGPTに渡して、応答を受け取る部分を実装します。
ChatGPTはAPIが公開されており、数行のコードでChatGPTを呼び出すことができます。
今回は、ずんだもんの口癖である「〜なのだ。」という応答で返して欲しかったので、ChatGPTの役割を設定する箇所に記載しておきました。
- 語尾に「〜なのだ」を付ける
- 返答はできるだけ短くする
- 友達口調で会話する
conversation_history.append(f"ユーザー: {question}")
prompt = "\n"
for message in conversation_history:
prompt += f"{message}\n"
prompt += "AI: "
messages = [{"role" : "system", "content":"あなたは「ずんだもん」という名前の女の子です。語尾に「なのだ。」を付けて。友達口調で会話して。返答はできるだけ短くして。"},
{"role" : "user", "content": prompt}
]ChatGPTとアレクサを繋げる具体的な方法については、以下の記事にて紹介していますので、ご参照いただければと思います。

またVOICEVOXの関数を呼び出す箇所で、それぞれのキャラクターの声に対応する番号を引数にすることで、声を変えることもできます。
#春日部つむぎの声でVOICEVOX合成
vv = Voicevox()
audio_url = vv.speak(text=text,speaker=8)
ChatGPTのAPIのモデル変更
以下の箇所を変更することで、ChatGPTのAPIのモデルも簡単に変更できます。
より最新版のAPIを使いたいという方は、使用料金は高くなってしまいますが、適宜変更してみるのも良いでしょう。
res=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens = 200
)
text = res['choices'][0]['message']['content']例えば「gpt-4-0125-preview」のモデルを使いたい場合は、以下のようにコードを修正します。
res=openai.ChatCompletion.create(
model="gpt-4-0125-preview",
messages=messages,
max_tokens = 200
)
text = res['choices'][0]['message']['content']ChatGPTのAPIの種類とそれぞれの利用料金は、以下の記事が参考になります。
CloudWatchによるエラーログ確認

CloudWatchのロググループにて、Lambda実行の際のエラー等を確認することができます。
もし挙動がおかしい場合は、確認してみると解決の参考になるでしょう。

例えば、以下のようなエラーが出た場合は、intentに関連する箇所がおかしいと分かります。
[ERROR] 2024-03-19T08:41:51.362Z a622fcfa-ab05-4cd9-9605-23885eabee75 module ‘ask_sdk_core.utils’ has no attribute ‘get_intent_name’
Intentの名前が不一致だったことが判明しました。
Intentの名前を一致させることで、エラーを解消することができます。

↓↓
Intentの名前を一致させる
↓↓

まとめ
ChatGPTとVoiceVoxを連携させてAlexaスキルを作成してみました。
ChatGPTとVOICEVOXを組み合わせることで、より人間らしさを感じる、自然な会話が可能になりました。
今回作成したものでは、応答に時間がかかったり、長い文章だとタイムアウトが発生するなどの課題もあるので、改善の余地はまだまだあります。
しかし、ChatGPTによる高性能な会話システムと、VOICEVOXによる音声合成処理を組み合わせることでAlexaとの対話がより魅力的で楽しいものになる可能性を感じました。
ChatGPTのAPIを使った役割設定では、ユーザーの特定の癖や口調を設定させて、それに合わせた応答を生成するようにすることも簡単にできます。
また、VoiceVoxにはさまざまなキャラクターの音声が含まれており、それらを使って様々なキャラクターに声を当てることも可能です。
それぞれの好みに合わせた設定が可能なので、多くの人が楽しめるスキルなのではないかと思っています。
今後もChatGPT含め、思いついたものを作っていければなと思います。
最後まで読んでいただきありがとうございました。























うまくわかりやすくまとまっていて素晴らしいと思います!
どこまでが有料なんだろう?というのが少し気になりますが(chatgpt以外)
やってみたいと思います
ありがとうございます!嬉しいです!
chatgpt以外だと、AWSサービス(Lambda、EC2、VPCエンドポイント、NATゲートウェイなど)が有料です。
特に今回のEC2スペックの場合、1時間ごとに数十円の料金がかかるので、使用時以外はEC2を停止しておく方が良いと思います。(NATゲートウェイも結構高いです・・・)