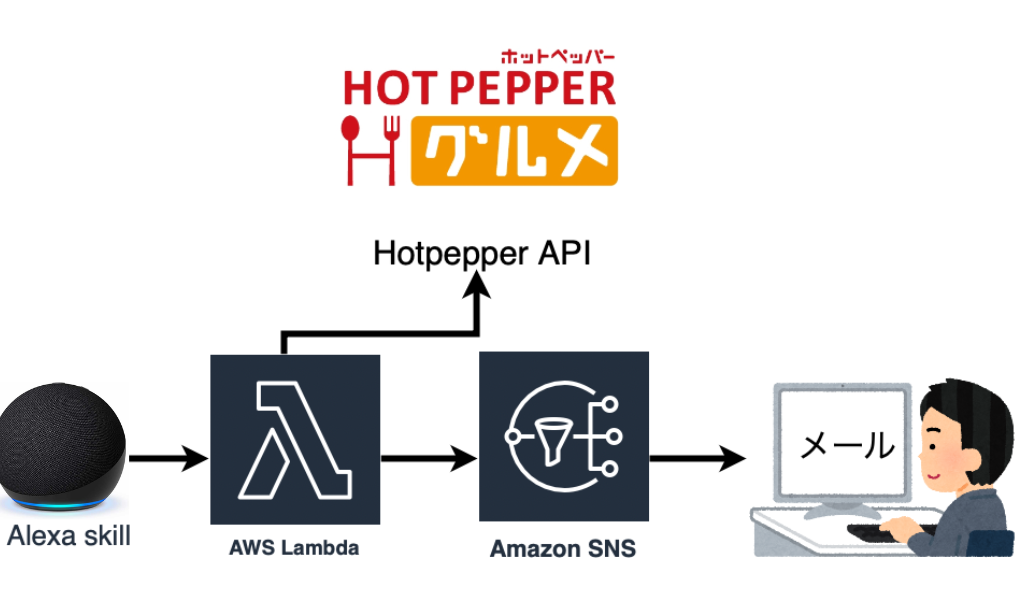
今回は、HOT PEPPERのAPIを使って店の情報をメールで送付してくれるAlexaのカスタムスキルを作成してみました。
メールアドレス送付は、Amazon SNS経由で行っています。

東京でおすすめのレストランを送って。

送ったよ。
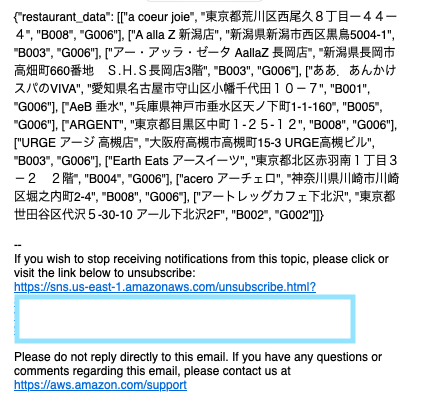
店情報が含まれた以下のようなメールが送付されてきました。
「東京」、「レストラン」という単語に基づいた店情報を探してくれます。
(なぜか、幾つか東京じゃない店が含まれていますが・・・)
大阪でおすすめのカフェを送って。
送ったよ。
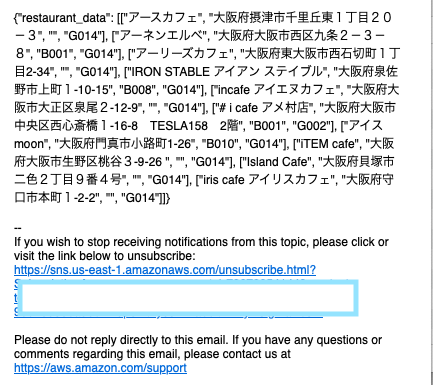
店情報が含まれた以下のようなメールが送付されてきました。
「大阪」、「カフェ」という単語に基づいた店情報を探してくれます。

こちらについて、処理の流れや実装方法をご紹介します。
Contents
処理の概要・流れ
- アレクサに探したい店の情報を入力
- AWS Lambdaにて「東京」、「レストラン」などのキーワードを元に、HotpepperのAPIにクエリを作成してリクエスト
- Amazon SNS経由で自身のメールアドレス宛に店情報を送付
HotpepperのAPI利用申請

- HOT PEPPERのAPI利用申請
以下のサイトより、HOT PEPPERのAPI利用申請をします。
登録したメールアドレスにて認証を行うことで、すぐに利用可能になります。
- HOT PEPPERのAPI新規登録
URL:https://webservice.recruit.co.jp/register

Lambdaで呼び出す環境変数は、Lambda関数の画面の「設定」→「「環境変数」から登録します。
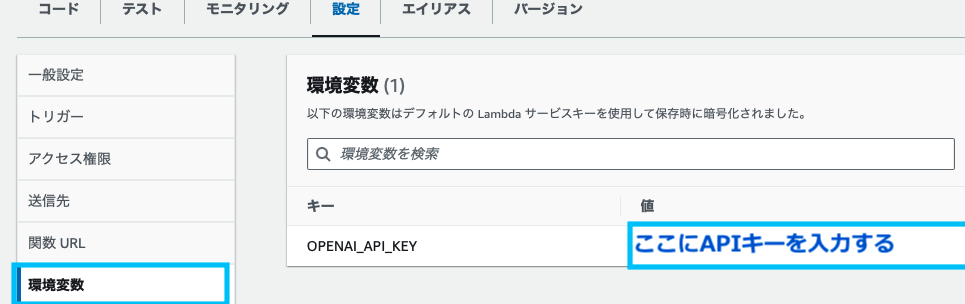
osコマンドを使用して、HOT PEPPERのAPIキーを環境変数を呼び出します。
#HOTPEPPER_API_KEYには、自身のAPIキーが入る
#環境変数をコードに直接記載するのは危険なので、osコマンドで呼び出す。
import os
HOTPEPPER_API_KEY = os.getenv('HOTPEPPER_API_KEY')Alexaのカスタムスキル作成

- アレクサスキルを作成
- アレクサスキルとLambdaの紐付け
アレクサスキルを作成
アレクサのカスタムスキルとは、自身が実装した処理に従ってアレクサが応答を返してくれるというものです。
自身でカスタムスキルを作成する場合、Alexa Developer Consoleから、カスタムスキルを作成することができます。
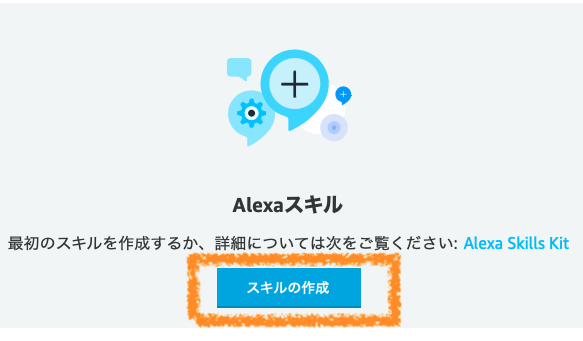
今回は、hotpepper_apiという名前でアレクサスキルを作成しました。
アレクサのカスタムスキルを呼び出すための名前は、「ホットペッパー」にしました。
「アレクサ、ホットペッパー」と呼びかけることでカスタムスキルを呼び出すことができます。

アレクサスキルとLambdaの紐付け
アレクサスキルのEndpointから確認できるDefault Regionは、Lambda関数のARNと一致していることを確認してください。


アレクサのカスタムスキル作成手順の詳細は、以下の記事をご確認ください。

Lambdaの作成・設定

- Pythonコード作成
- レイヤーの設定(Pythonライブラリ)
- IAMロールの設定
Pythonコードの作成
主要なファイルは、以下に記載の通りです。
コードはgithubに挙げていますので、必要に応じてご参照ください。
- リンク:https://github.com/my-repo-441/alexa-hotpepper
- コード:
・lambda_function.py(Alexaから呼び出されるコード)
・areas_extractor.py
(地名をAPIのコードに変換する関数(例:東京→Z011))
・genres_extractor.py
(ジャンルをAPIのコードに変換する関数(例:カフェ→G014)))
・area_list.txt
(コード変換対象の地名一覧)
・genres_list.txt
(コード変換対象のジャンル一覧)
コードをLambda関数の画面にて作成します。
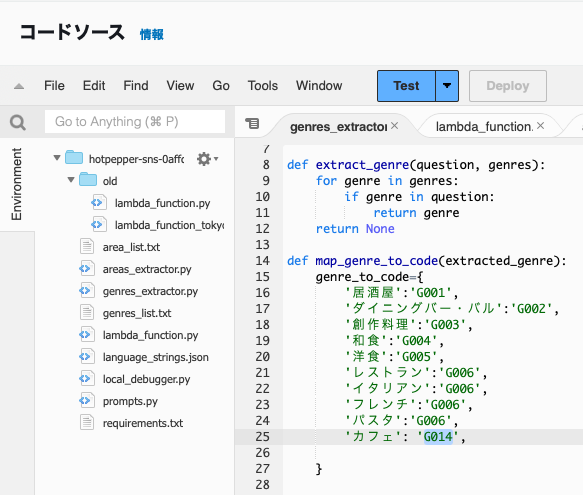
lambda_function.py
Alexaスキルを呼び出した時に実行されるpythonファイルです。
HotPepperIntentHandlerクラスを追加しています。
このクラスの中身の処理が実行されます。
class HotPepperIntentHandler(AbstractRequestHandler):
def can_handle(self, handler_input):
return ask_utils.is_intent_name("HotPepperIntent")(handler_input)
def handle(self, handler_input):
slots = handler_input.request_envelope.request.intent.slots
question = slots["question"].value
api_key = HOTPEPPER_API_KEY
areas = load_genres("area_list.txt")
genres = load_genres("genres_list.txt")
extracted_area = extract_area(question, areas)
extracted_genre = extract_genre(question, genres)
area_code = map_area_to_code(extracted_area)
genre_code = map_genre_to_code(extracted_genre)
print(extracted_area)
print(area_code)
print(extracted_genre)
print(genre_code)
i_start = 1
restaurant_datas=[]
#while True:
query = {
'key': api_key,
'large_area':area_code, # 東京
'genre':genre_code,
'order': 1, #名前の順
'start': i_start, #検索結果の何番目から出力するか
'count': 10, #最大取得件数
'format': 'json'
}
url_base = 'http://webservice.recruit.co.jp/hotpepper/gourmet/v1/'
responce = requests.get(url_base, query)
result = json.loads(responce.text)['results']['shop']
if len(result) == 0:
#break
print("0")
for restaurant in result:
restaurant_datas.append([restaurant['name'], restaurant['address'], restaurant['budget']['code'], restaurant['genre']['code']])
i_start += 100
print(i_start)
print(restaurant_datas)
# SNSクライアントの作成
sns_client = boto3.client('sns')
# SNSトピックのARN
topic_arn = 'arn:aws:sns:us-east-1:自身のSNSトピックのARN'
# restaurant_datasをJSON文字列に変換
message = json.dumps({'restaurant_data': restaurant_datas}, ensure_ascii=False)
print(message)
# SNSトピックにメッセージをパブリッシュ
response = sns_client.publish(
TopicArn=topic_arn,
Message=message,
Subject='Restaurant Data'
)
print(response)
speak_output = "送ったよ。"
return (
handler_input.response_builder
.speak(speak_output)
.ask("他に質問はありますか?")
.response
)
sb = SkillBuilder()
# Register intent handlers
sb.add_request_handler(HotPepperIntentHandler())- HotPepperIntentを追加しておく
(SLOT TYPEはAMAZON.Launguageとする。)
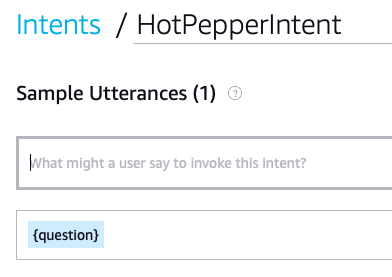

lambda_function.pyにおいて、このIntentと同じ名前のクラスが呼び出されます。
SLOT TYPEに指定した「AMAZON.Language」はAlexaの音声入力から何かしらの言語が検出されたら、このインテントを実行するという意味です。
areas_extractor.py
アレクサからの音声入力で対象の地名が含まれていれば、HOT PEPPERのAPIに対応しているジャンルコードに紐づける。
- HOT PEPPERのAPIの地名コード一覧は以下を参照
リクエストURL:https://webservice.recruit.co.jp/hotpepper/large_area/v1/?key=sample
(その他のAPIリファレンス:https://webservice.recruit.co.jp/doc/hotpepper/reference.html)
#テキストファイルに含まれる地名を1行ずつ読み込んでareasに格納する
def load_areas(file_path):
with open(file_path, "r", encoding="utf-8") as file:
print(file)
areas = [line.strip() for line in file if line.strip()]
return areas
#アレクサからの音声に、areas内の地名が含まれていれば、地名を返す。
#地名が含まれていなければ、Noneを返す。
def extract_area(question, areas):
for area in areas:
if area in question:
return area
return None
#地名をHotpepperのAPIにおける地名コードに対応づける。
def map_area_to_code(extracted_area):
area_to_code={
'東京':'Z011',
'大阪':'Z023'
}
return area_to_code.get(extracted_area)genres_extractor.py
アレクサからの音声入力で対象のジャンルが含まれていれば、HOT PEPPERのAPIに対応しているジャンルコードに紐づける。
- HOT PEPPERのAPIのジャンルコード一覧は以下を参照
リクエストURL:https://webservice.recruit.co.jp/hotpepper/genre/v1/?key=sample
(その他のAPIリファレンス:https://webservice.recruit.co.jp/doc/hotpepper/reference.html)
#テキストファイルに含まれるジャンルを1行ずつ読み込んでgenresに格納する
def load_genres(file_path):
with open(file_path, "r", encoding="utf-8") as file:
print(file)
genres = [line.strip() for line in file if line.strip()]
return genres
#アレクサからの音声に、genres内のジャンルが含まれていれば、ジャンルを返す。
#ジャンルが含まれていなければ、Noneを返す。
def extract_genre(question, genres):
for genre in genres:
if genre in question:
return genre
return None
#ジャンルをHotpepperのAPIにおけるジャンルコードに対応づける。
def map_genre_to_code(extracted_genre):
genre_to_code={
'居酒屋':'G001',
'ダイニングバー・バル':'G002',
'創作料理':'G003',
'和食':'G004',
'洋食':'G005',
'レストラン':'G006',
'イタリアン':'G006',
'フレンチ':'G006',
'パスタ':'G006',
'カフェ': 'G014',
}
return genre_to_code.get(extracted_genre)area_list.txt
アレクサからの音声入力で、このテキストファイルに含まれる地名を検索対象としている。
#今回は、大阪と東京のみareasに格納されるように設定
大阪
東京genre_list.txt
アレクサからの音声入力で、このテキストファイルに含まれるジャンルを検索対象としている。
#以下のジャンルをgenresに格納されるように設定
居酒屋
中華
和食
レストラン
フレンチ
イタリアン
ラーメン
カフェ
スイーツ
パスタレイヤーの設定
以下をLambdaのレイヤーに登録します。
上記は、Pythonの実行に必要なライブラリをzip化したものです。
- リンク:https://github.com/my-repo-441/alexa-hotpepper/tree/master/layer
- ライブラリが入ったzip:
・python.zip
上記のzipファイルをLambdaのレイヤーとして登録します。
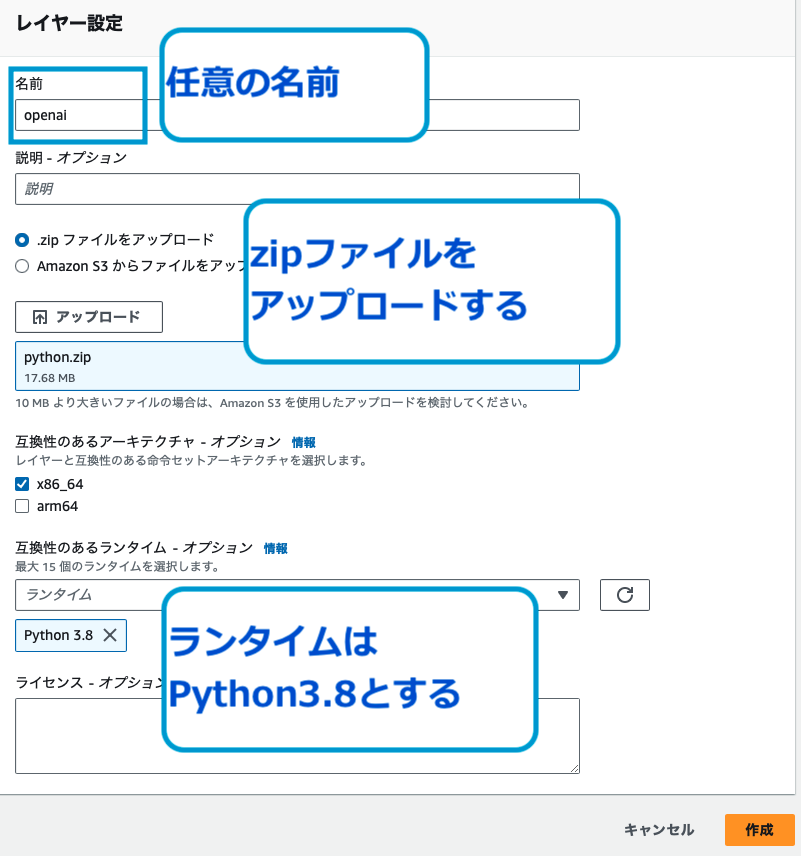
Lambdaコンソール画面から直接アップロードする方法
Lambdaのコンソール画面から、レイヤーを選択します。

「レイヤーの作成」を押下し、githubからダウンロードしたzipファイルをアップロードしてください。この時、ランタイムはPython3.8としてください。
Lambda関数画面の一番下にある「レイヤーの追加」を選択し、今回用意した3つのzipファイルで作成したレイヤーを追加します。

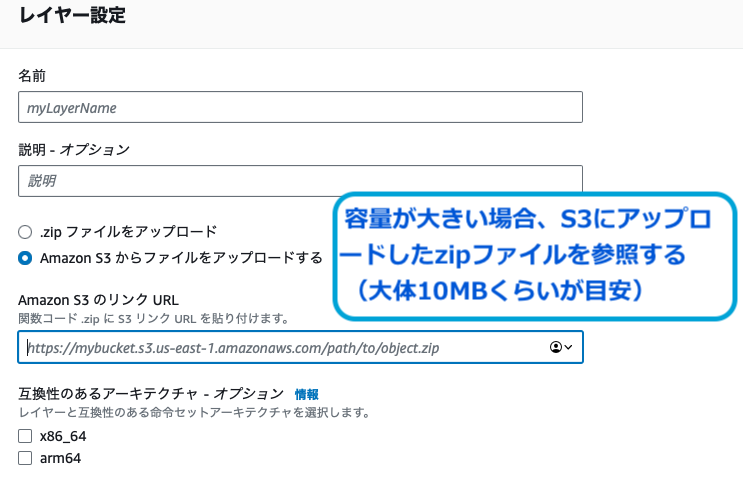
S3にアップロードして参照する方法
S3にzipファイルをアップロードして参照する方法もあります。
今回は、ライブラリの容量が大きいため、このS3オブジェクトを参照します。
IAMロールの設定
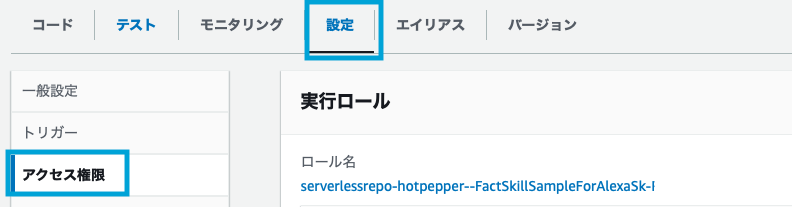
Lambda関数画面の「設定」→「アクセス権限」から実行ロール名をコピーします。
IAMコンソール画面から、Lambdaで使われているロールを選択します。
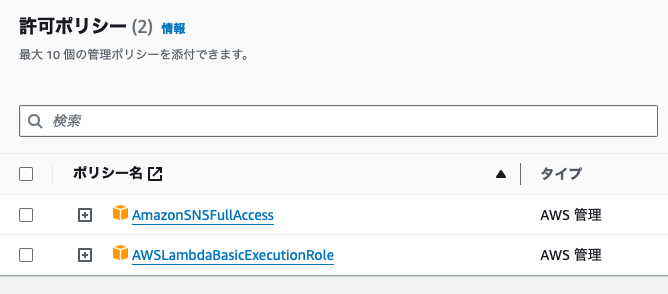
許可ポリシーに「AmazonSNSFullAccess」を追加します。
Amazon SNSの設定

- SNSトピックを作成
- 自身のメールをサブスクライブ
SNSトピックを作成
トピックの作成を選択します。
タイプはスタンダードを選択し、名前は任意でOKです。
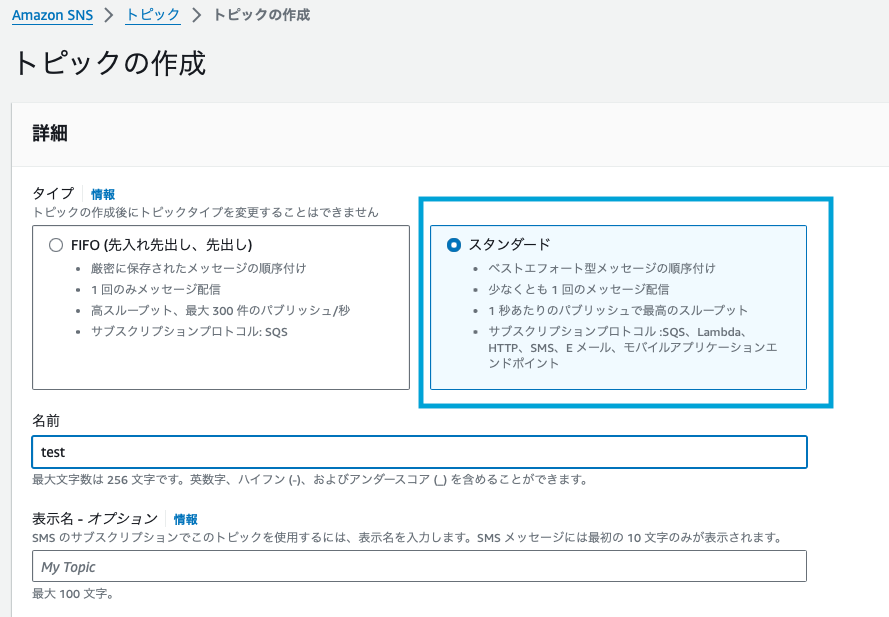
トピックの作成を押下します。
自身のメールをサブスクライブ
作成したトピックの画面で、サブスクリプションの作成を押下します。
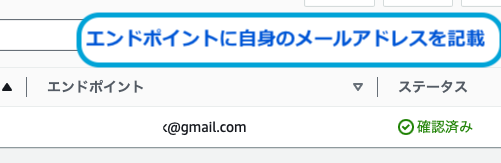
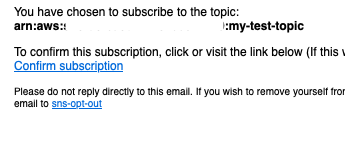
エンドポイントのメールアドレス宛に、以下のように承認の確認メールがきます。Confirm subscriptionを押下することで、SNSからのメールを受け取ることができるようになります。
まとめ
今回は、HOT PEPPERのAPIから連携されたデータは、json形式でメールに配信しています。
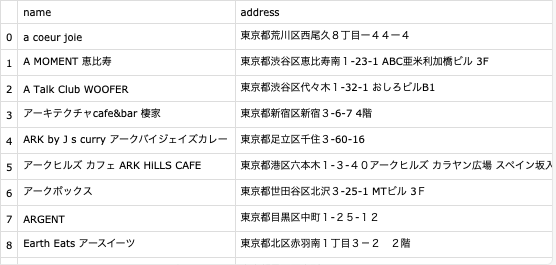
連携されたデータをそのままjsonで配信した場合、以下のように少し読みづらいです。

読みづらさを解消するために、json形式のデータをCSV形式にすることが考えられます。
CSV形式であれば、以下のように読みやすい形にすることができます。
CSV形式への変換については、pandasライブラリを使おうと思いました。
しかしpandasは容量が大きなライブラリのため、Lambdaでレイヤーを登録する際に、サイズオーバーエラーが出てしまいました。

pandasによるデータ形式の変更処理は、EC2やGlueを使う方法が考えられます。
今回の検証では実施していませんが、改めてCSV形式でのメール配信もそのうち試してみようと思います。
また今回は、地名とジャンルのみで店の検索を行いましたが、HOT PEPPERのAPIには他にも様々な機能があるようなので、さらに上手な活用方法も考えてみようかと思みたいと思います。
最後まで読んでいただきありがとうございました。





















アレクサからHOT PEPPERのAPIを呼び出してみた結果がこちらです。
店情報のメールが送信された後に、アレクサから「送ったよ。」というメッセージが返ってくるように指定しています。