

VOICEVOXで声を変えることでアバターと会話してる感がより強くなるね。
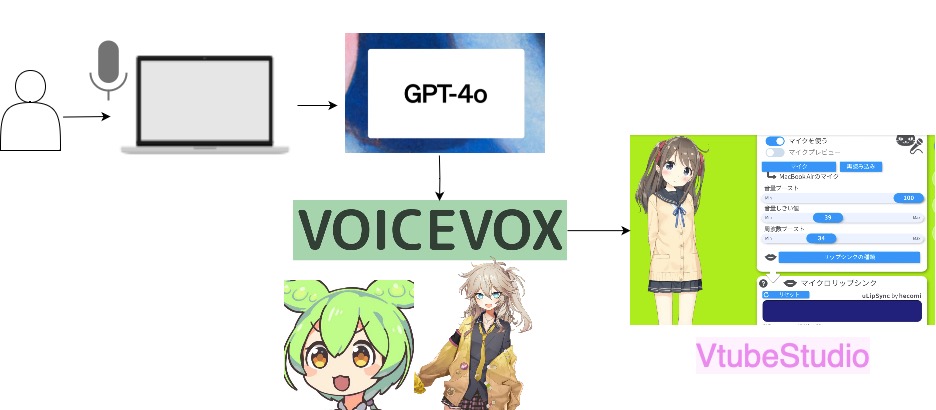
本記事では、ChatGPTから出力されたテキストをVOICEVOXで音声合成し、それをVtubeStudioのアバター口元の動きと連動させる手順を解説します。
Contents
構成と処理の流れ
- Vtube Studio
- VOICEVOX
- gpt-4o APIアクセス
- OBS
- マイク(PCに内蔵されていればOK)
- 前提条件
- VOICEVOXのコンテナイメージが起動していること
- VtubeStudioが起動し、APIの設定がONになっていること
- 処理の流れ
- ユーザーの質問を音声で入力し、文字起こしする。
- ChatGPTを使用して回答を生成する。
- 生成されたテキストをVOICEVOXで処理し、音声データを作成する。
- 音声データを解析して、口の動きのパラメータを抽出する。
- VtubeStudioのLipsync APIを使用して、キャラクターの口の動きを制御する。
VOICEVOXのコンテナイメージ起動
VOICEVOXは、入力したテキストを様々なキャラクターの声に変換して出力してくれるテキスト読み上げソフトウェアです。
YouTubeなどで「ずんだもん解説動画」が流行していることからも、その人気がうかがえます。

今回の実装ではVOICEVOXのコンテナイメージを利用しています。
コンテナイメージを用いることで、どのOSからでもVOICEVOXを起動できます。
#1. コンテナイメージのダウンロード
docker pull voicevox/voicevox_engine:cpu-ubuntu20.04-latest
#コンテナの起動
docker run --rm -it -p '127.0.0.1:50021:50021' voicevox/voicevox_engine:cpu-ubuntu20.04-latest
VOICEVOXのイメージの起動が成功すると、以下のような画面が表示されます。

音声入力の文字起こし
- sounddevice: マイクからの音声入力をリアルタイムで処理するために使用します。
- audioop: 音声データの音量(RMS値)を計算するために使用します。
- numpy: 録音データを効率的に処理するために使用します。
- speech_recognition: Google Speech Recognition APIを利用して音声をテキストに変換するために使用します。
- 音声の録音と無音検出:
- マイクから音声を録音し、一定期間の無音状態を検出して録音を停止します。
- 無音状態を検出するために、音声の音量をリアルタイムで計算します。
- 録音データの文字起こし:
- 録音された音声データをテキストに変換します。
- Google Speech Recognition APIを使用して、音声を日本語のテキストに変換します。
def record_until_silence(threshold=200, chunk_size=1024, silence_limit=1, sample_rate=44100):
"""無音検出で録音を終了する"""
print("質問を音声で入力してください: ")
frames = []
silent_chunks = 0
max_silent_chunks = int(silence_limit * sample_rate / chunk_size)
stop_recording = False
def callback(indata, frame_count, time_info, status):
nonlocal silent_chunks, frames, stop_recording
if status:
print(status)
frames.append(indata.copy())
rms = audioop.rms(indata[:, 0], 2) # Root Mean Square (RMS) value is used to measure loudness
#print(rms)
if rms < threshold:
silent_chunks += 1
else:
silent_chunks = 0
if silent_chunks > max_silent_chunks:
print("無音検出、録音を停止します")
stop_recording = True
with sd.InputStream(samplerate=sample_rate, channels=1, dtype='int16', callback=callback, blocksize=chunk_size):
while not stop_recording:
sd.sleep(100)
print("録音終了")
audio_data = np.concatenate(frames, axis=0)
return audio_data, sample_rate
def recognize_speech_from_audio_data(audio_data, sample_rate):
"""録音データから音声をテキストに変換する"""
recognizer = sr.Recognizer()
audio = sr.AudioData(audio_data.tobytes(), sample_rate, 2)
response = {
"success": True,
"error": None,
"transcription": None
}
try:
response["transcription"] = recognizer.recognize_google(audio, language='ja-JP')
except sr.RequestError:
response["success"] = False
response["error"] = "Google Speech Recognition APIにアクセスできませんでした"
except sr.UnknownValueError:
response["success"] = False
response["error"] = "音声を認識できませんでした"
return response
GPT-4oの概要

GPT-4o(Omni)は、テキストや画像の入力を受け、多言語に対応し、視覚認識能力を備えた最先端のマルチモーダルAIモデルです。テキスト生成速度は従来のモデルの2倍、コストも50%削減されています。
GPT-4o(「o」は「omni」を意味します)は、私たちの最も高度なモデルです。
GPT-4o – https://platform.openai.com/docs/models/gpt-4o
これはマルチモーダルであり(テキストや画像の入力を受け付け、テキストを出力します)、GPT-4 Turboと同じ高い知能を持ちながら、はるかに効率的です。テキスト生成の速度は2倍速く、コストは50%安くなっています。さらに、GPT-4oは視覚認識においても非英語言語においても、他のモデルに比べて最高のパフォーマンスを発揮します。GPT-4oは、有料顧客向けにOpenAI APIで利用可能です。GPT-4oの使用方法については、テキスト生成ガイドをご覧ください。
| MODEL | DESCRIPTION | CONTEXT WINDOW | TRAINING DATA |
| gpt-4o | GPT-4o Our most advanced, multimodal flagship model that’s cheaper and faster than GPT-4 Turbo. Currently points to gpt-4o-2024-05-13. | 128,000 tokens | Up to Oct 2023 |
| gpt-4o-2024-05-13 | gpt-4o currently points to this version. | 128,000 tokens | Up to Oct 2023 |
res = client.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=1000
)GPTおよびDALL-E3のAPIを使用するには、OpenAIのAPIキーが必要です。
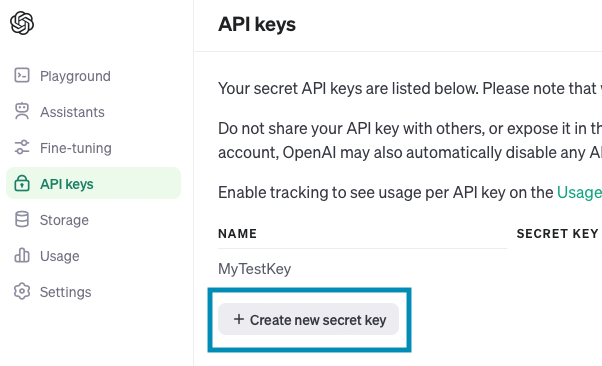
まだAPIキーを取得していない方は、OpenAIのAPI発行画面からAPIキーを発行しましょう。
Create new secret keyを押下します。
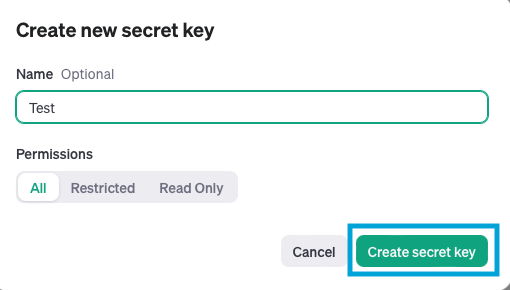
「Create secret key」を押下します。
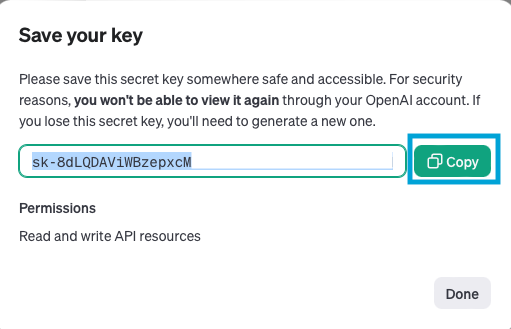
作成されたキーをコピーしておきます。
画面を閉じてしまうとキーがコピーできなくなるため、注意してください。
VtubeStudioのアバターとの連動方法

VOICEVOXを使って生成された音声を元に、ChatGPTのAPI連動して音声データを生成し、それをVtubeStudioのLipsync APIを通じてキャラクターの口の動きに反映させます。
これにより、ユーザーは自然な会話と連動したキャラクターの動きを実現できます。
- 前提条件
- VtubeStudioのリップシンクを設定しておく
- 流れ
- VOICEVOXからの音声出力を取得します。
- 音声データをVtubeStudioのリップシンクAPIに送信します。
VtubeStudioのAPIを起動し、リップシンキングを使います。
APIの起動をONすることで、外部のソースと連携することができます。
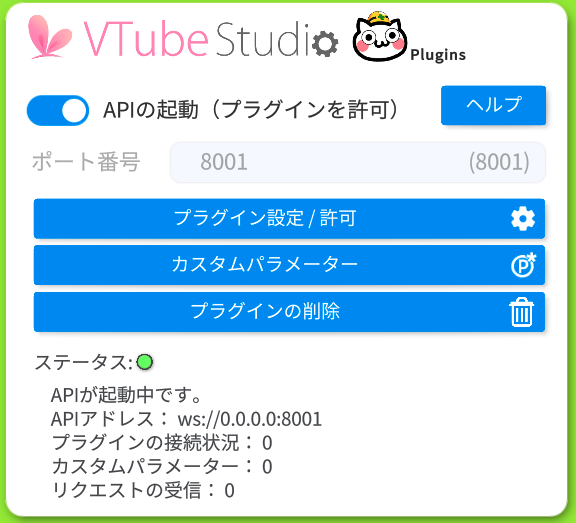
VOICEVOXから出力された音声に合わせて、キャラクターの口を動かします。
音声に合わせて口を動かすには、リップシンクの設定を実施します。
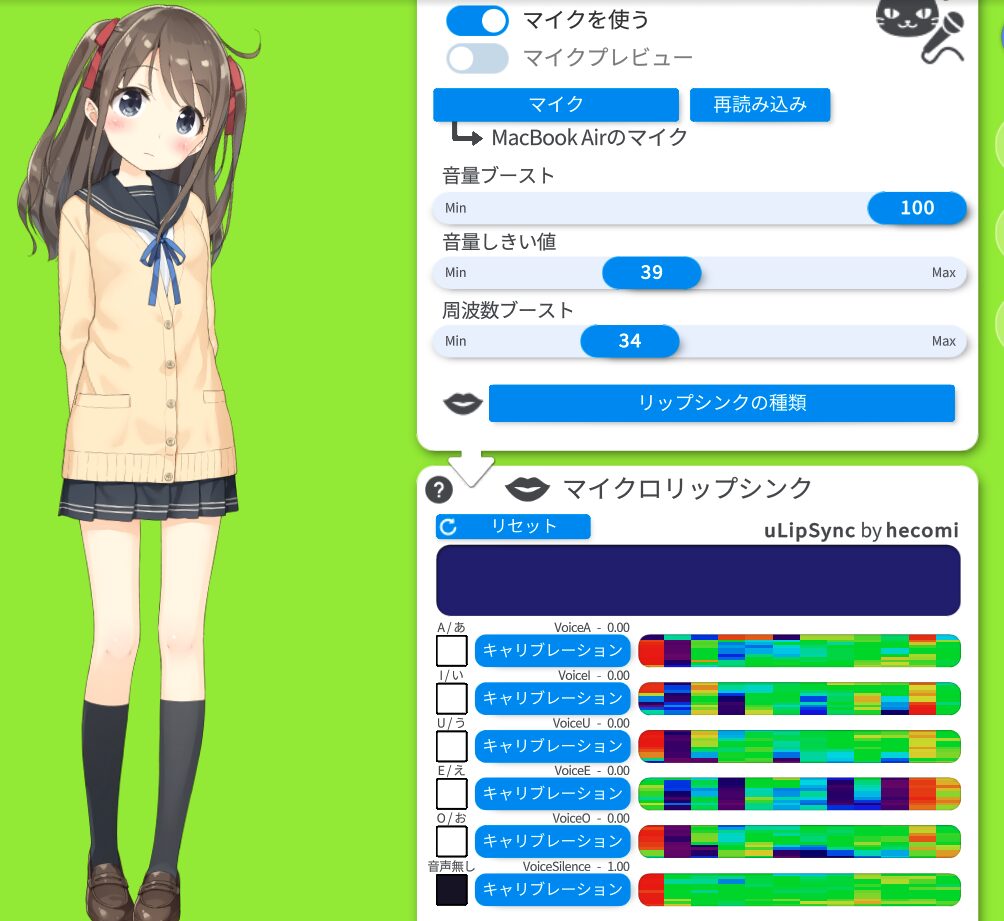
VTube Studioの公式マニュアルには、リップシンクの設定方法が詳しく説明されています。公式のサポートページで最新の情報を確認できます。
VTube Studio公式マニュアル Lipsync
声とキャラクターを変えて実行
VOICEVOXの声とVtubeStudioのキャラクターを変えて実行することもできます。
試しに猫のアバター(VOICEVOX:櫻歌ミコ)で実行してみました。
OBSでVtubeStudioのキャラクターを透過させる
OBSとVtubeStudioを組み合わせることで、アプリケーションの画面にキャラクターを透過して表示させることもできます。
アバターと会話しながら、ライブ配信してみても面白いかもしれません。
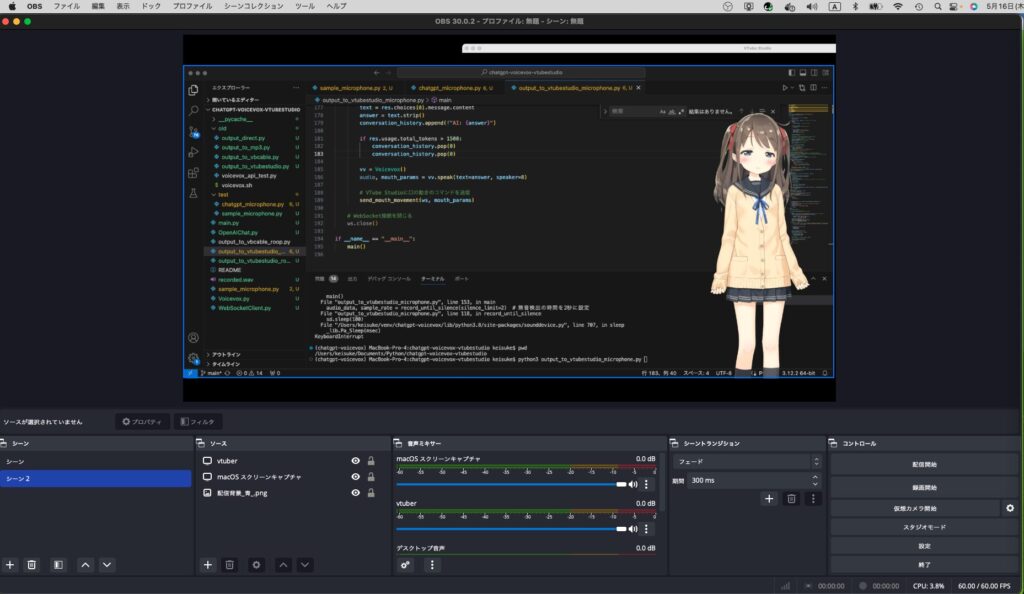
以下の手順で実施します。
- VtubeStudioの設定を変更する
- VtubeStudioを開き、背景をクロマキー(通常は緑や青)に設定します。設定メニューで「背景色」オプションを見つけて、クロマキーとして使用する色を選択してください。
- OBS Studioをインストールする
- OBS Studioは無料のオープンソースソフトウェアで、スクリーンキャプチャやストリーミングに使用されます。公式サイトからダウンロードしてインストールしてください。
- OBS Studioでウィンドウキャプチャを設定する
- OBS Studioを開き、「ソース」欄の「+」ボタンをクリックし、「ウィンドウキャプチャ」を選択します。
- VtubeStudioのウィンドウを選択します。
- クロマキーを適用する
- 「ソース」欄で作成したウィンドウキャプチャを右クリックし、「フィルター」を選択します。
- 「エフェクトフィルター」の「+」ボタンをクリックし、「クロマキー」を選択します。
- 設定した背景色(クロマキー色)を選択し、キャラクターのみが表示されるように調整します。
- 仮想カメラを使用する
- OBS Studioで「仮想カメラ」を開始します(「コントロール」メニューから選択できます)。
- これにより、OBS Studioで処理された映像を仮想カメラとして他のアプリケーションで使用できるようになります。
まとめ
GPT-4oのレスポンス速度は速いです。
しかしVOICEVOXの音声合成に時間がかかり、結果としてレスポンスが変えてくるまでに時間がかかり過ぎている感じがします。
改良の余地がありそうですが、レスポンスの速度を早めれば、より自然にアバターと会話できるようになりそうです。
最後まで読んでいただきありがとうございました。
ではでは。





















今回はGPT-4oをVtubeStudioとVOICEVOXと組み合わせることで、アバターと会話ができるようにしてみました。