
最新の生成AIがどれほどのものか、見ものだね。
今回は、OpenAIのAPI「DALL-E 3」と「Vision」を組み合わせて漫画の作成をしてみます。
Contents
VisionとDALL-E 3のAPIの使い方
Visionについて
画像からプロンプト生成できる、image-to-textのOpenAIのAPIです。
APIではGPT-4Vまたはgpt-4-vision-previewというモデルが使用されます。
試しに、以下のような画像を入力として実行してみます。
今回の場合、入力画像はURLで指定しています。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
#ここに画像のURLを入力する。
"image_url": {
"url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-6ctCbGpXizEe2iVIO0X6AiO3/user-34JYIi4w60JwZ0pf4FRH5vZJ/img-zYWUGkmAQchaCXw6FP1GKicz.png?st=2024-03-25T23%3A26%3A51Z&se=2024-03-26T01%3A26%3A51Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2024-03-25T21%3A02%3A28Z&ske=2024-03-26T21%3A02%3A28Z&sks=b&skv=2021-08-06&sig=kI0mjWz8pIQMumw7N6eEWZ8t8M8ntrM15qXuyordchk%3D",
},
},
],
}
],
max_tokens=300,
)
↓↓
visionによるプロンプト生成
↓↓
Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='This image depicts a dramatic scene, heavily stylized and likely influenced by Japanese art and culture. In the foreground, two warriors or samurai are standing on a pile of swords atop a rocky outcrop, creating a sense of a historic or epic moment. The background shows a futuristic cityscape with tall skyscrapers, some old traditional buildings, and a massive, detailed full moon dominating the sky above.\n\nThe scene blends elements of tradition with futuristic or dystopian themes, suggesting a story or concept that merges different times or worlds. The artwork is monochromatic with intricate details and uses light and shadows to create a stark contrast. The clouds and the way light spills across the scene give it a dynamic and moody atmosphere.', role='assistant', function_call=None, tool_calls=None))上記のようなプロンプトが出力されます。
プロンプトは英語で出力されるので、日本語訳して内容を確認してみます。
↓↓
contentを日本語訳
↓↓
‘この画像はドラマチックな場面を描いており、日本の芸術や文化の影響を受けていると思われる。前景では、2人の武士かサムライが岩場の上に積まれた刀の上に立っており、歴史的な、あるいは壮大な瞬間を感じさせる。背景には、高い高層ビルが立ち並ぶ近未来的な街並みと、古い伝統的な建物、そして上空を支配する巨大で詳細な満月が描かれている。作品は単色でありながら細部まで精巧に描かれ、光と影を使って激しいコントラストを生み出している。雲と光のこぼれ方がダイナミックでムーディーな雰囲気を醸し出している。’

高い精度で画像からプロンプト生成できていることが分かります。
DALL-E 3について
プロンプトから画像生成ができるtext-to-image形式のOpenAIのAPIです。
Visionとは逆の機能だね。
試しに、「ルネサンス期の人物がスマートフォンを使っている様子」というプロンプトで画像生成してみました。
response = client.images.generate(
model="dall-e-3",
#ここにプロンプトを記載
prompt ="Renaissance figure using a smartphone.",
size="1024x1024",
quality="standard",
n=1,
)以下のような画像が生成されました。

プロンプトに忠実に画像生成できていますね。
以下の記事にも、DALL-E 3の概要や、Pythonコードによる実装例を記載しています。
APIの使い方や生成できる画像が気になる方は、ぜひご覧いただければと思います。

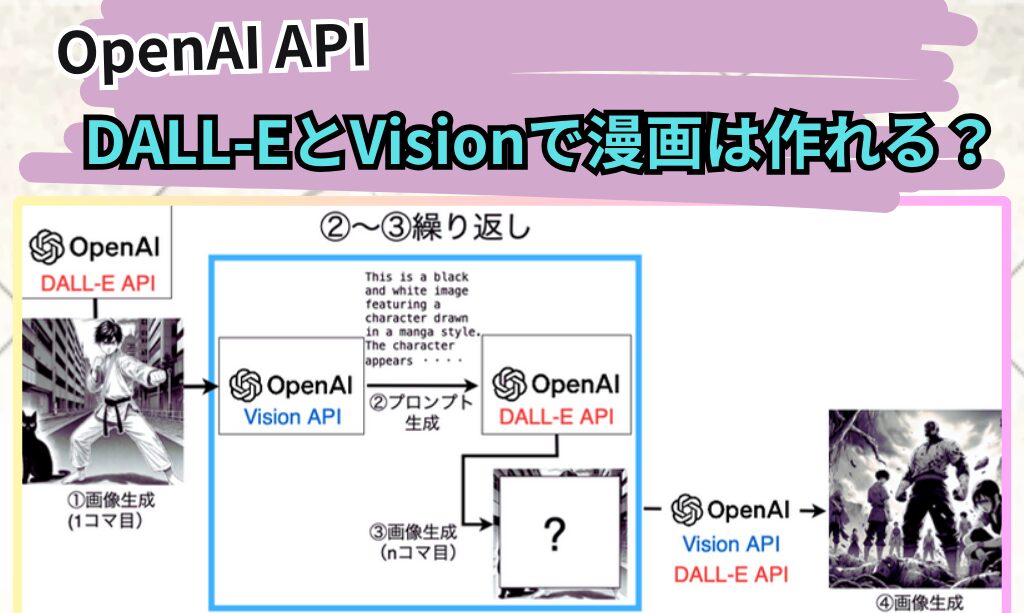
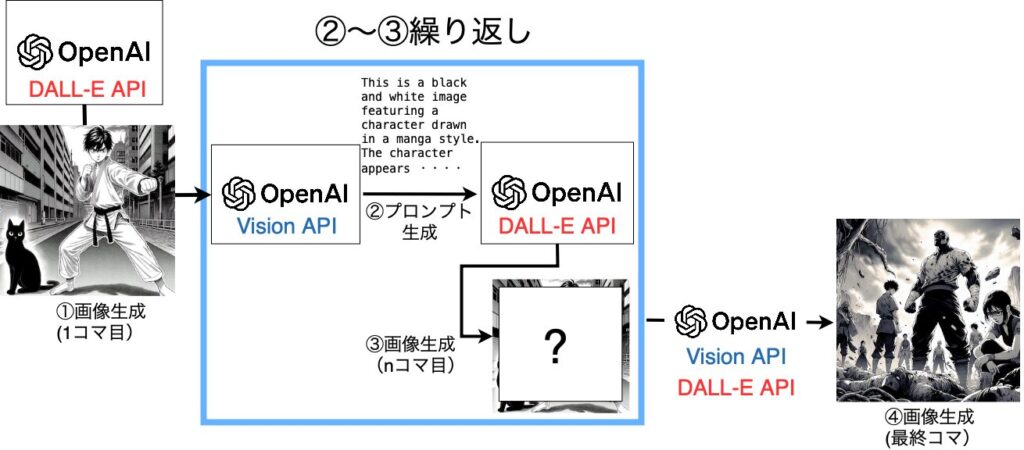
漫画生成の流れ
OpenAIのAPIを使った漫画生成の処理の流れは以下です。
- DALL-E 3で漫画の1コマ目を生成
- Visionを使って、1コマ目の画像のプロンプトを生成
- 2で生成したプロンプトを元に、DALL-E 3で次のコマを生成
2〜3の処理を、漫画のページ数に応じて繰り返す。
- VisionとDALL-E 3で漫画の最終コマを生成
下記のようなコードで処理を実装しました。
必要なライブラリは、openaiとrequestsの2つのみです。
from openai import OpenAI
import requests
client = OpenAI()
#漫画のページ数
n_pages = 6
#漫画の設定
world_building = "Far in the future, space has become a new frontier for mankind. People lived on numerous stars and built a space society where different cultures and technologies intersected. However, unknown dangers lurk in the vastness of space, and many threaten the peace. The Guardians of Starlight who protect each star system, play an active role."
# 指定されたページ数だけ画像生成を繰り返す
for i in range(1, n_pages + 1):
if i==1:
response_img = client.images.generate(
model="dall-e-3",
prompt = f"This is first frame of a {n_pages}-page shonen battle manga. Draw the first frame. World building is as follows:'{world_building}'",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response_img.data[0].url
print(image_url)
# 画像をダウンロードするためのリクエストを送信
response = requests.get(image_url)
# リクエストが成功した場合(HTTPステータスコード200)
if response.status_code == 200:
# バイナリモードで画像ファイルを開き、内容を書き込む
with open(f"downloaded_image{i}.png", "wb") as file:
file.write(response.content)
print("Image successfully downloaded and saved.")
else:
print(f"Failed to download image. Status code: {response.status_code}")
elif i == n_pages:
response_vision = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
],
max_tokens=300,
)
# 結果の 'content' のみを出力
print(response_vision.choices[0].message.content)
prompt = response_vision
response_img = client.images.generate(
model="dall-e-3",
prompt = f"This is the final frame of a {n_pages}-page shonen battle manga. Draw a continuation of the previous page. The previous page situation are as follows:'{prompt}' World building is as follows:'{world_building}'",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response_img.data[0].url
print(image_url)
print("fin.")
# 画像をダウンロードするためのリクエストを送信
response = requests.get(image_url)
# リクエストが成功した場合(HTTPステータスコード200)
if response.status_code == 200:
# バイナリモードで画像ファイルを開き、内容を書き込む
with open(f"downloaded_image{i}.png", "wb") as file:
file.write(response.content)
print("Image successfully downloaded and saved.")
else:
print(f"Failed to download image. Status code: {response.status_code}")
else:
response_vision = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
],
max_tokens=300,
)
# 結果の 'content' のみを出力
print(response_vision.choices[0].message.content)
prompt = response_vision
response_img = client.images.generate(
model="dall-e-3",
prompt = f"This is {i} frame of a {n_pages}-page shonen battle manga. Draw a continuation of the previous page. The previous page situation are as follows:'{prompt}' World building is as follows:'{world_building}'",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response_img.data[0].url
print(image_url)
# 画像をダウンロードするためのリクエストを送信
response = requests.get(image_url)
# リクエストが成功した場合(HTTPステータスコード200)
if response.status_code == 200:
# バイナリモードで画像ファイルを開き、内容を書き込む
with open(f"downloaded_image{i}.png", "wb") as file:
file.write(response.content)
print("Image successfully downloaded and saved.")
else:
print(f"Failed to download image. Status code: {response.status_code}")
実際に試してみた
まずは以下のようなプロンプトで試してみます。
「これは{n_pages}ページのバトル漫画の1コマです。{i}番目のコマを描いてください。ひとつ前のコマの描写は以下の通りです{prompt}。」
response_img = client.images.generate(
model="dall-e-3",
prompt = f" This is the final frame of a {n_pages}-page manga. Draw the final frame. The description of one previous panel is as follows {prompt}.",
size="1024x1024",
quality="standard",
n=1,
)- n_pages:漫画のページ数
- i:生成するページ
- prompt:ひとつ前の生成画像をvisionでプロンプト化したもの







う〜〜ん・・・全然ダメだ。

全部のコマで同じような画像が生成されちゃってるね。
プロンプトを変更して実行
プロンプトを修正してみました。
「これは{n_pages}ページのバトル少年マンガの{i}コマ目です。次に説明する描写の続きに関連付けられる{i}番目のコマを描いてください。{prompt}」

最初の検証では、コマに変化がありませんでした。
前の描写を反映しつつ、新しい場面を画像生成してくれるを期待。
response_img = client.images.generate(
model="dall-e-3",
prompt = f"This is one frame of a {n_pages}-page battle shonen manga. Draw the {i}-th frame that can be associated with the continuation of the description described next. {prompt}",
size="1024x1024",
quality="standard",
n=1,
)
1コマ目がコチラです。

2コマ目がコチラです。

3コマ目がコチラです。

4コマ目がコチラです。


1回目の検証よりは、生成される画像に変化が出たね。
構図や登場人物に多少の変化が出ました。
しかしこの程度の変化では、到底漫画とは呼べません。
さらにプロンプトを修正して再実行
プロンプトの指示をシンプルにしてみました。
「{n_pages}ページの少年バトルマンガの{i}コマです。前のページの続きを描いてください。前ページの状況は次の通り:'{prompt}’ 」
「前のページの続きを描いてください。」というシンプルなプロンプトに変更してみました。
response_img = client.images.generate(
model="dall-e-3",
prompt = f"This is the final frame of a {n_pages}-page shonen manga. Draw a continuation of the previous page. The previous page situation are as follows:'{prompt}'",
size="1024x1024",
quality="standard",
n=1,
)
生成された画像がコチラです。









今回はだいぶ漫画っぽくなったね。
コマごとの描写バリエーションも増えたね。
登場人物に一貫性がなかったり、同じようなコマがあったり、白黒とカラーが混じっていたりと課題はあります。
ただ最初に比べると、だいぶ漫画感は出ました。
漫画の設定を追加して再実行
最後に、漫画の設定を追加して、実行してみます。
漫画の設定は、ChatGPTに考えてもらいます。
少年誌に掲載する漫画の設定を考えて
タイトル:『星影の守護者(せいえいのしゅごしゃ)』
【世界観】 遥か未来、宇宙が人類の新たなフロンティアとなった時代。人々は数多の星々に住み、異なる文化や技術が交差する宇宙社会を築いていた。しかし、この広大な宇宙には未知の危険も潜んでおり、平和を脅かす存在も少なくない。そんな中、各星系を守護する「星影の守護者」たちが活躍する。
world_building = "Far in the future, space is the new frontier for mankind. People lived on numerous stars and built space societies where different cultures and technologies intersected. However, there are unknown dangers lurking in this vast universe, and not a few threaten the peace. Against this backdrop, the "Guardians of Starlight," who protect each star system, play an active role."
DALL-Eに渡すプロンプトには、「漫画の設定に関する内容」を加えます。
「これは{n_pages}ページの少年バトル漫画の{i}コマ目です。前のページの続きを描いてください。前ページの状況は次の通り:'{prompt}’ 設定は次の通り:'{world_building}’」
response_img = client.images.generate(
model="dall-e-3",
prompt = f"This is first frame of a {n_pages}-page shonen battle manga. Draw the first frame. World building is as follows:'{world_building}'",
size="1024x1024",
quality="standard",
n=1,
)
生成された画像がコチラです。








漫画の設定を指示することで、より漫画っぽいものが生成できました。
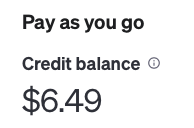
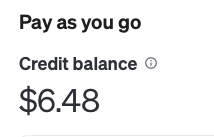
APIの使用料金
今回用いたOpenAIのAPI利用料金の目安です。
visionの使用料金
visionのAPIは、生成されるトークンに応じた課金です。
百万トークンで10.00$です。
| gpt-4-1106-vision-preview | $10.00 / 1M tokens | $30.00 / 1M tokens |
1枚の画像に対してvisionを使用した際の料金は、約$0.01$でした。
(max_tokensを300に設定した場合)
response_vision = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
],
max_tokens=300,
)↓↓
生成されたプロンプト
↓↓
Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='This image depicts a dramatic scene, heavily stylized and likely influenced by Japanese art and culture. In the foreground, two warriors or samurai are standing on a pile of swords atop a rocky outcrop, creating a sense of a historic or epic moment. The background shows a futuristic cityscape with tall skyscrapers, some old traditional buildings, and a massive, detailed full moon dominating the sky above.\n\nThe scene blends elements of tradition with futuristic or dystopian themes, suggesting a story or concept that merges different times or worlds. The artwork is monochromatic with intricate details and uses light and shadows to create a stark contrast. The clouds and the way light spills across the scene give it a dynamic and moody atmosphere.', role='assistant', function_call=None, tool_calls=None))10$で1Mトークンなので、0.01$だと1000トークンです。
今回は300トークンに制限しているため、実際は0.01$にも満たないくらいの利用料金だと思います。
DALL-EのAPI使用料金
DALL-EのAPIの使用料金は、画像の生成枚数、画質、画像サイズによって変わります。
こちらはvisionよりも料金形態が分かりやすいですね。
| Model | Quality | Resolution | Price |
| DALL·E 3 | Standard | 1024×1024 | $0.040 / image |
| Standard | 1024×1792, 1792×1024 | $0.080 / image | |
| DALL·E 3 | HD | 1024×1024 | $0.080 / image |
| HD | 1024×1792, 1792×1024 | $0.120 / image | |
| DALL·E 2 | 1024×1024 | $0.020 / image | |
| 512×512 | $0.018 / image | ||
| 256×256 | $0.016 / image |
まとめ
今回は、OpenAIのVisionとDALL-E 3を組み合わせることで、漫画生成できるか検証してみました。
- 漫画っぽいものは生成できた
Visionは非常に精度が高かったです。
DALL-E 3に関してもプロンプトに記載した内容をもとに質の高い画像生成ができました。
最初の検証では、全然漫画っぽいものを作ることができませんでした。
しかしプロンプトを修正していくことで、最終的には漫画っぽいものを生成することができました。(あくまで漫画っぽいものです。)
実際に世に出回っている漫画のクオリティには到底及ばないと感じました。
魅力的なキャラ設定、世界観、構図、背景などは生成AIでは再現するのは難しいです。
(プロンプトを突き詰めることで、今回の検証よりもさらに精度は高くできるとは思いますが。)

そもそもセリフないしね。
人を惹きつける作品を生み出す漫画家はやっぱりすごいね!
漫画家の凄さを再認識できました。
最後に課題をまとめて、本記事は終了にしようと思います。
最後まで読んでいただきありがとうございました。
- 同じようなコマが生成されてしまう
- キャラデザインに一貫性がない
- コマ間のつながりやストーリ性が分かりづらい
- セリフがない
- 構図のバリエーションが少ない




















今回は、OpenAIが公開しているAPI「Vision」と「DALL-E」を組み合わせて、漫画ができるか試してみたよ。