
こちらの画像は、実際にDALL-Eのプロンプトで画像生成したものです。
プロンプトは、「ルネサンス期の人物がスマートフォンを使っている様子」です。


OpenAIの最新の画像生成AIってことで、流石のクオリティだね!

どんな画像でも生成してくれるから、まるで魔法みたいだよ。
本記事では、OpenAIのAPIとして提供されている「DALL·E 3」を使ってみました。
Contents
OpenAIのAPI DALL-Eについて
プロンプトから画像生成ができるtext-to-image形式のOpenAIのAPIです。
「DALL·E 2、DALL·E 3」という2つのバージョンが利用可能です。
ちなみに本記事を2024年3時点での最新モデルは「DALL·E 3」で、2023年11月にリリースされています。
- テキストプロンプトに基づいて、ゼロから画像を作成する (DALL-E 3 と DALL-E 2)
←本記事でご紹介する機能 - 新しいテキストプロンプトに基づき、既存の画像の一部をモデルに置き換えて、画像の編集バージョンを作成する (DALL-E 2 のみ)
- 既存の画像のバリエーションを作成する(DALL-E 2 のみ)
2024年3月時点では、DALL-E 3はプロンプトからの画像生成のみ可能みたいです。
実際に使ってみた
前準備
- Python環境をセットアップします。
- OpenAIのAPIキーを作成します。
- 自身のPython環境からOpenAIのAPIキーを呼び出します。
- サンプルコードを実行します。
DALL-E3をAPI経由で使用するためには、OpenAIのAPIキーが必要です。
まずは、OpenAIのAPI発行画面からAPIキーを発行しましょう。
Create new secret keyを押下します。
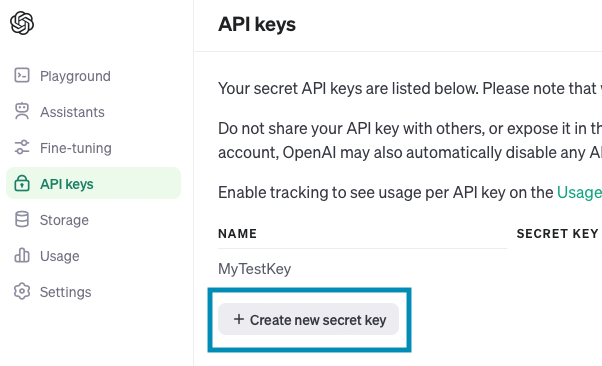
「Create secret key」を押下します。
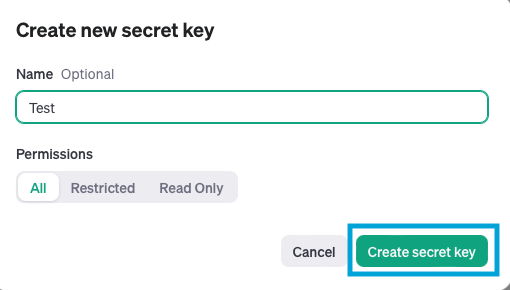
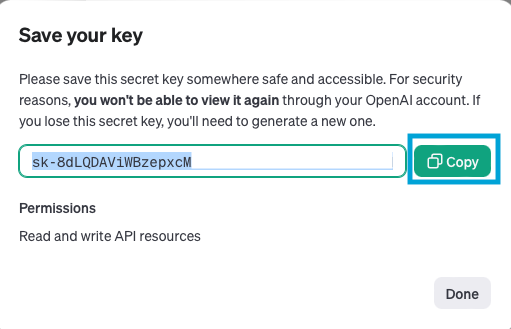
作成されたキーをコピーしておきます。
画面を閉じてしまうとキーがコピーできなくなるため、注意してください。
今回は、pythonのvenvで仮想環境を作成し、実行します。
#仮想環境を作成
python -m venv ~/venv/openai-img-gene
#仮想環境のアクティベート
source ~/venv/openai-ima-gene/bin/activateOpenAIのライブラリをpipでインストールします。
#openaiのライブラリをインストール
(openai-img-gene)pip install openai先ほど取得したOpenAIのAPIキーを設定します。
#openaiのAPIキーを設定
(openai-img-gene)export OPENAI_API_KEY='your_api_key_here'ここまでで前準備は完了です。
サンプルプログラムを実行
公式のAPIドキュメントにあったサンプルプログラム(Python)を実行してみます。
APIを使うためのコードはたったの数行です。
今回は、サンプルプログラムに記載されていた「a white siamese cat(白いシャム猫)」を生成してみました。
from openai import OpenAI
client = OpenAI()
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
print(image_url)上記のPythonコードを実行します。
#Pythonコードの実行(sample.pyの部分は、自身のファイル名を記載。)
(openai-img-gene)python sample.py実行が成功すると、画像のURLが表示されます。

このURLにアクセスすることで、生成された画像を表示することができます。
同じpromptで、3つの画像を生成してみました。



絵のタッチやポーズとかはランダムに生成されるんだね。
そうだね。同じポーズや画風の画像を生成して欲しい場合は、promptの内容を細かくすることで、調整もできそうだよ。
promptの条件を増やして実行
- a white siamese cat(白いシャム猫)
- realistic(現実的)
- sleep(睡眠)
- kitten(子猫)
from openai import OpenAI
client = OpenAI()
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat, realistic, sleep, kitten",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
print(image_url)
もういちど3つの画像生成をしてみました。



promptの内容に沿った画像が生成されているね。
色々なpromptを試してみる
少し変わり種のpromptでも試してみました。
response = client.images.generate(
model="dall-e-3",
#海賊の帽子をかぶった猫が、一切れのピザに乗って七つの海を航海している
prompt="A cat wearing a pirate hat, sailing the seven seas on a slice of pizza.",
size="1024x1024",
quality="standard",
n=1,
)プロンプトには、「海賊の帽子をかぶった猫が、一切れのピザに乗って七つの海を航海している」と記載しています。
生成された画像がこちらです。

海賊猫がピザに乗りながら航海している何とも愛らしい画像が生成できました。
response = client.images.generate(
model="dall-e-3",
#ビクトリア朝の庭でティーパーティーをするロボットと恐竜。
prompt="A robot and a dinosaur having a tea party in a Victorian garden.",
size="1024x1024",
quality="standard",
n=1,
)プロンプトには、「ビクトリア朝の庭でティーパーティーをするロボットと恐竜」と記載しています。
生成された画像がこちらです。

response = client.images.generate(
model="dall-e-3",
#19世紀のロンドンがサイバーパンクの都市になった様子
prompt="How 19th century London became a cyberpunk city",
size="1024x1024",
quality="standard",
n=1,
)プロンプトには、「19世紀のロンドンがサイバーパンクの都市になった様子」と記載しています。
生成された画像がこちらです。

ロンドンのレトロな街並みにSFの世界観が組み合わさった画像です。
response = client.images.generate(
model="dall-e-3",
#時間の流れを可視化したアートワーク
prompt="Artwork visualizing the passage of time",
size="1024x1024",
quality="standard",
n=1,
)プロンプトには、「時間の流れを可視化したアートワーク」と記載しています。
生成された画像がこちらです。

抽象的なプロンプトでも、それっぽい画像が生成できました。
時間の流れが春夏秋冬で表現されています。
無茶振りにも対応して画像生成できるのは凄いね!
DALL-E 3のパラメータ
DALL-E 3で使用できるパラメータ一覧です。
- model (‘dall-e-2’ or ‘dall-e-3’): 使用するモデル。
- style (‘natural’ or ‘vivid’): 生成される画像のスタイル。デフォルトはvivid。
- quality (‘standard’ or ‘hd’): 画質
- prompt (str): 生成する画像の説明
- n (int): 生成する画像枚数(dall-e-3はn=1のみサポート)
- size (…): 生成する画像サイズ(1024×1024, 1792×1024, or 1024×1792)
- response_format (‘url’ or ‘b64_json’): 生成する画像のフォーマット。デフォルトは”url”
- user (str): エンドユーザーを表す一意の識別子で、OpenAIの監視と不正利用の検出に役立つ。
最低限、model, prompt, size, quality, nの値を指定していれば大丈夫です。
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat, realistic, sleep, kitten",
size="1024x1024",
quality="standard",
n=1,
)DALL-E 3では、より高画質な画像生成も可能です。
(DALL-E 2ではstandard画質のみ生成可能でした。)
デフォルトでは、画像は
OpenAI API Reference – Image generationstandard画質で生成されますが、DALL-E 3を使用する場合は画質を設定できます。quality: "hd"に設定することで、ディテールが強調されます。正方形の標準画質の画像が最も速く生成されます。
DALL-EのAPI利用料金
DALL-EのAPIの使用料金は、画像の生成枚数、画質、画像サイズによって変わります。
| Model | Quality | Resolution | Price |
| DALL·E 3 | Standard | 1024×1024 | $0.040 / image |
| Standard | 1024×1792, 1792×1024 | $0.080 / image | |
| DALL·E 3 | HD | 1024×1024 | $0.080 / image |
| HD | 1024×1792, 1792×1024 | $0.120 / image | |
| DALL·E 2 | 1024×1024 | $0.020 / image | |
| 512×512 | $0.018 / image | ||
| 256×256 | $0.016 / image |

DALL-E 3の方がDALL-E 2よりも、2倍くらい料金が高いです。
まとめ
OpenAIのDALL-E 3を実際に使ってみた感想としては、「想像以上に質の高い画像が生成できて楽しかった」です。
promptの内容が非現実的でも、抽象的でも、それっぽい画像が生成できます。
要は、アイディア次第でどんな画像も作れちゃうってことです。
想像力と言語化能力が試されますね。
自分の空想を文字にするだけで、それが画像になります。
本当に魔法みたいだなと思いました。
今後もOpenAI、ないしは生成AIの動向には注目していきたいですね。
最後まで読んでいただきありがとうございました。
「OpenAI Image Generation APIの公式ドキュメント」や「DALL-E 3とは何か?」については、以下のURLから確認できます。
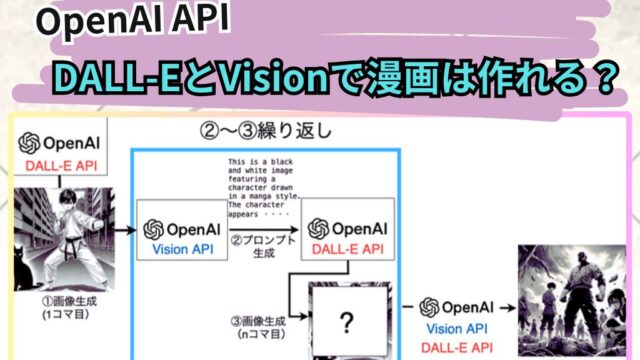
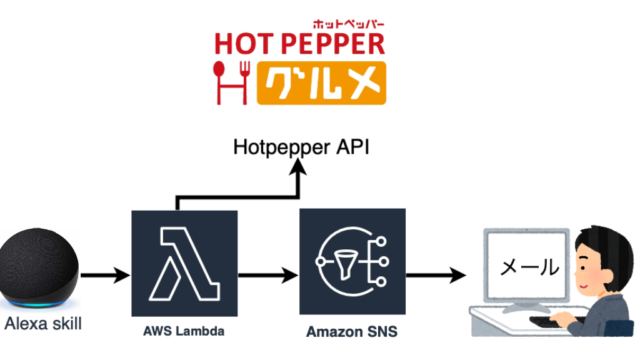
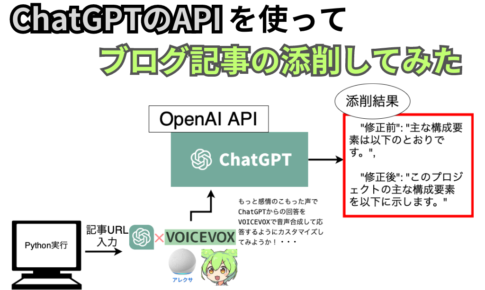


















OpenAIのAPIを使うことで簡単に画像生成ができるよ。